
О востребованности визуализации данных
Спрашивает Игорь Трафимович:
Я довольно активно слежу за тематическими блогами о визуализации данных и у меня сложилось впечатление, что создание всех этих потрясающих интерактивных работ — не слишком прибыльное занятие, ведь для большинства бизнес-задач достаточно простейших барчартов, которые можно сделать в Excel без участия дизайнера.
Расскажи, востребована ли визуализация данных на рынке и насколько перспективной ты сама видишь эту область?
Я не знаю, как оценить перспективность области. Если 99,9% преступлений в Лондоне раскрывают полицейские Скотленд-ярда, делает ли это работу Шерлока Холмса менее перспективной?

Визуализация — это сверх-мощный инструмент. Она наглядно показывает огромные объёмы данных, проявляет закономерности, которые никто не надеялся найти, сворачивает
При этом визуализация, как Шерлок, решает очень узкий круг задач — запутанные дела со сложными, многомерными данными, в которых скрываются полезные для бизнеса знания. Такие задачи найдутся далеко не в каждой компании, а если и найдутся, от них необязательно зависит успех бизнеса, и даже когда зависит, лица, принимающие решения, могут не знать о том, что задачу можно решить с помощью визуализации данных. Рынок крошечный, риск остаться без работы велик.
Вот что делаем я и моя команда, чтобы чувствовать себя хорошо.
- Главное правило, занимаемся только визуализацией данных (сродни правилу балерин зарабатывать только балетом :-)
- Когда заказов нет, делаем бесплатные прототипы в рамках рубрики «Вопрос-ответ» или сами придумываем себе задачи.
- Отвечаем на вопросы в блоге.
- Выступаем на конференциях (в прошлом году был перерыв).
- Записываем видео-лекции, организуем учебные курсы.
- Рассказываем о работе всем, кто готов слушать.
Всё это, и немного везения, приводит в лабораторию клиентов мечты с самыми запутанными и интересными задачами. Чем больше задач мы решаем, тем искуснее используем визуализацию данных и тем уверенне чувствуем себя на рынке. Это единственный известный мне путь к востребованности в этой области.
Кстати, мы в Лаборатории данных ищем веб-разработчика. Вакансия открыта до 31 января.
Присылайте вопросы о визуализации данных на почту: data@datalaboratory.ru. Следующая заметка выйдет 1 февраля.
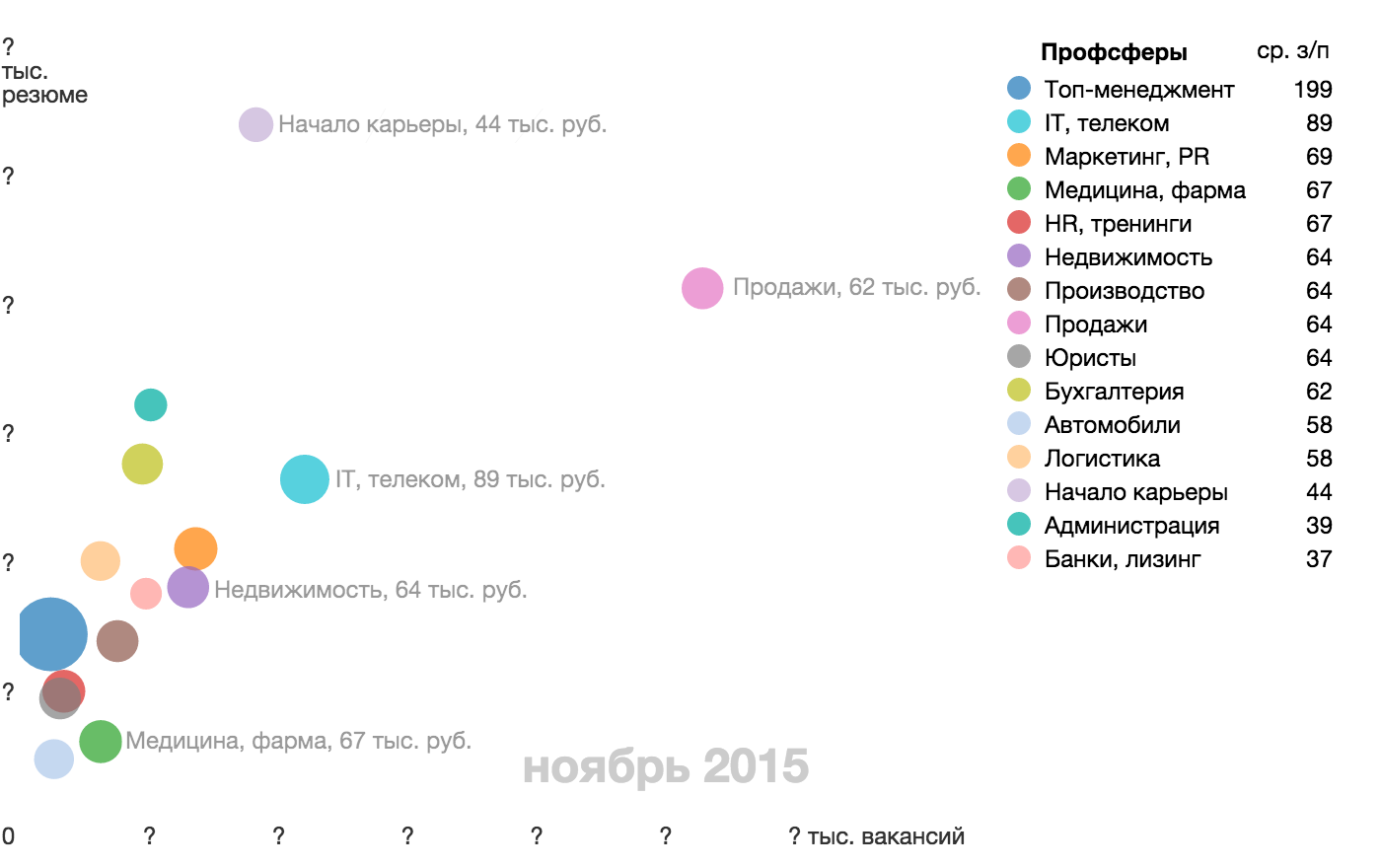
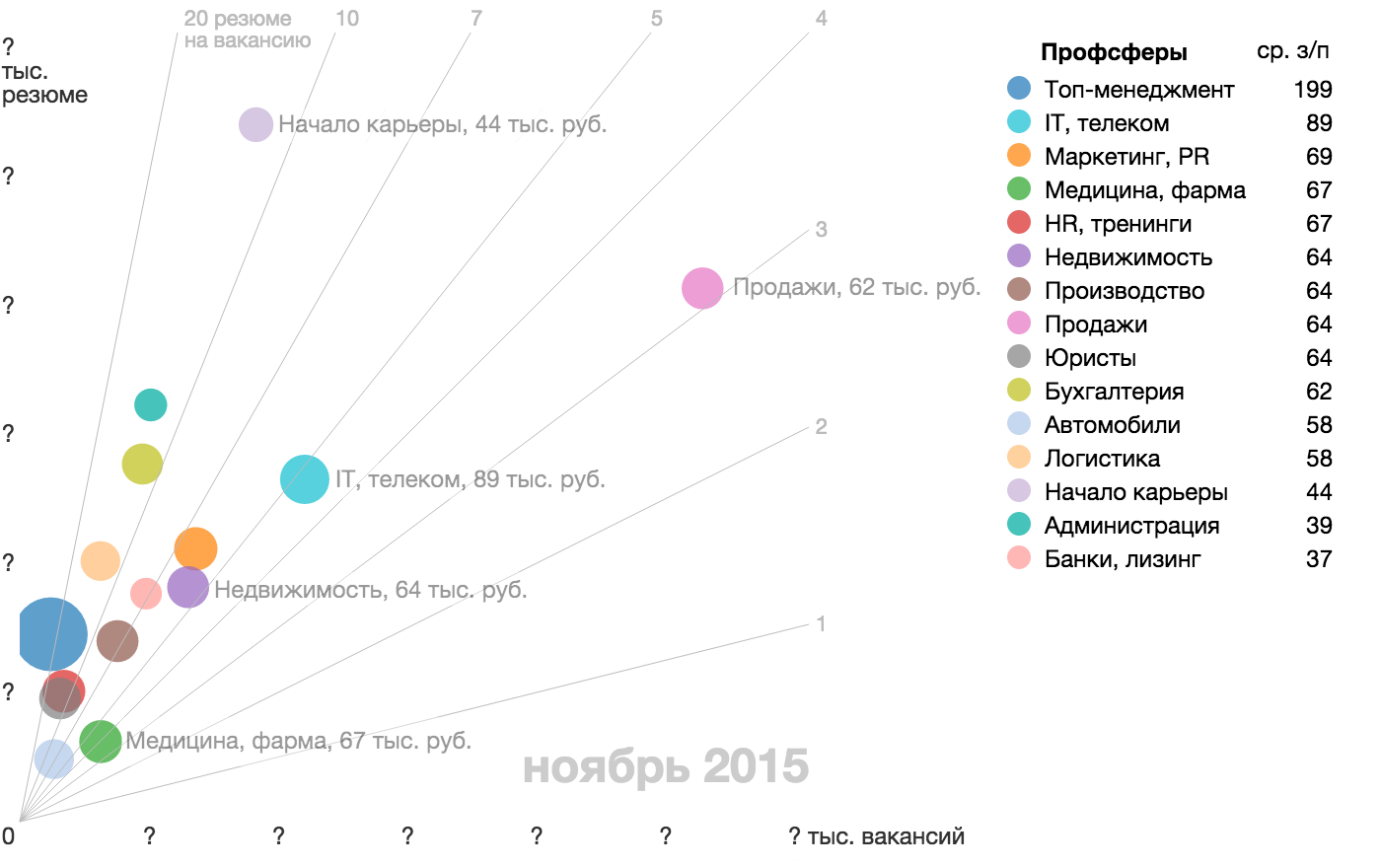
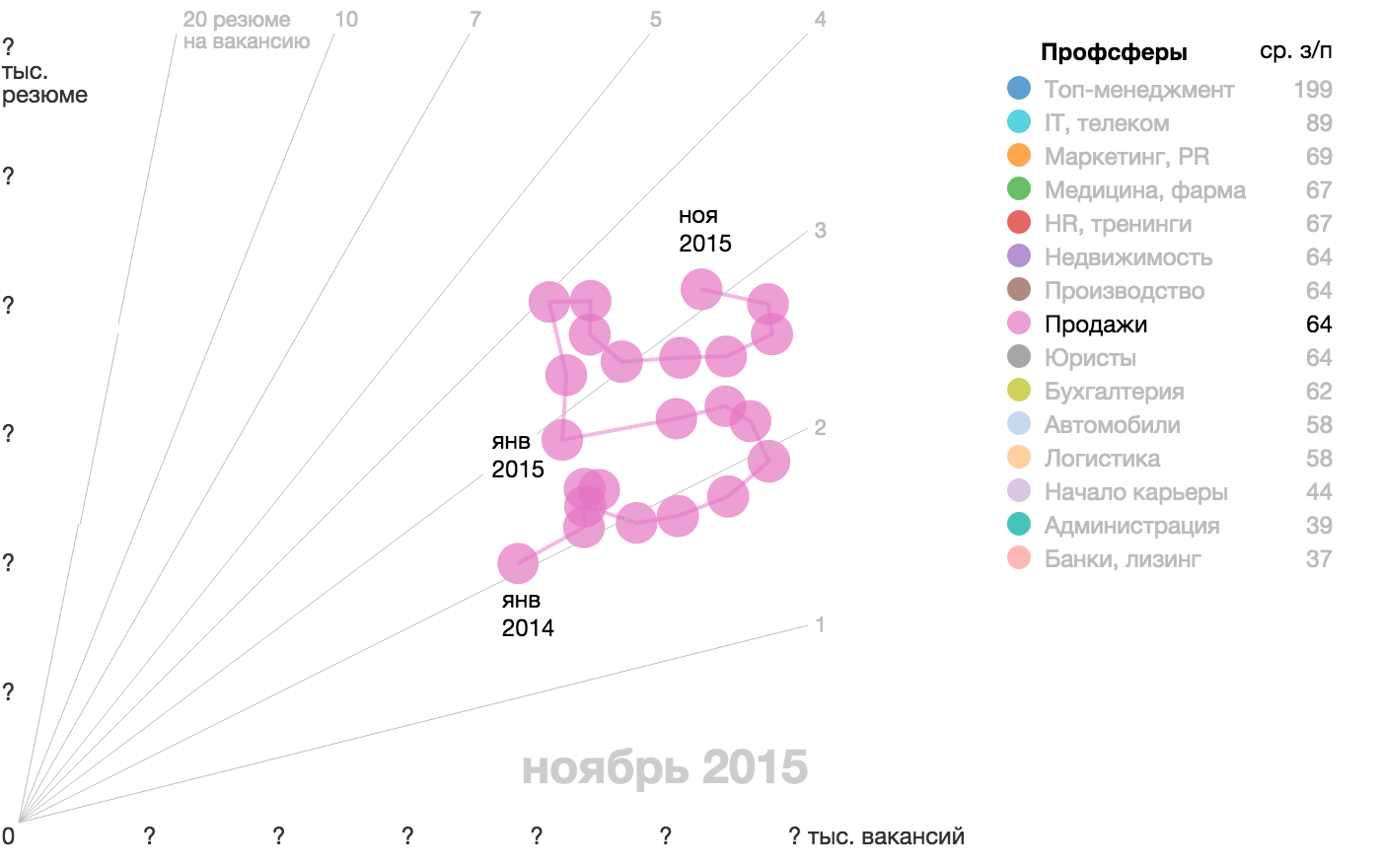
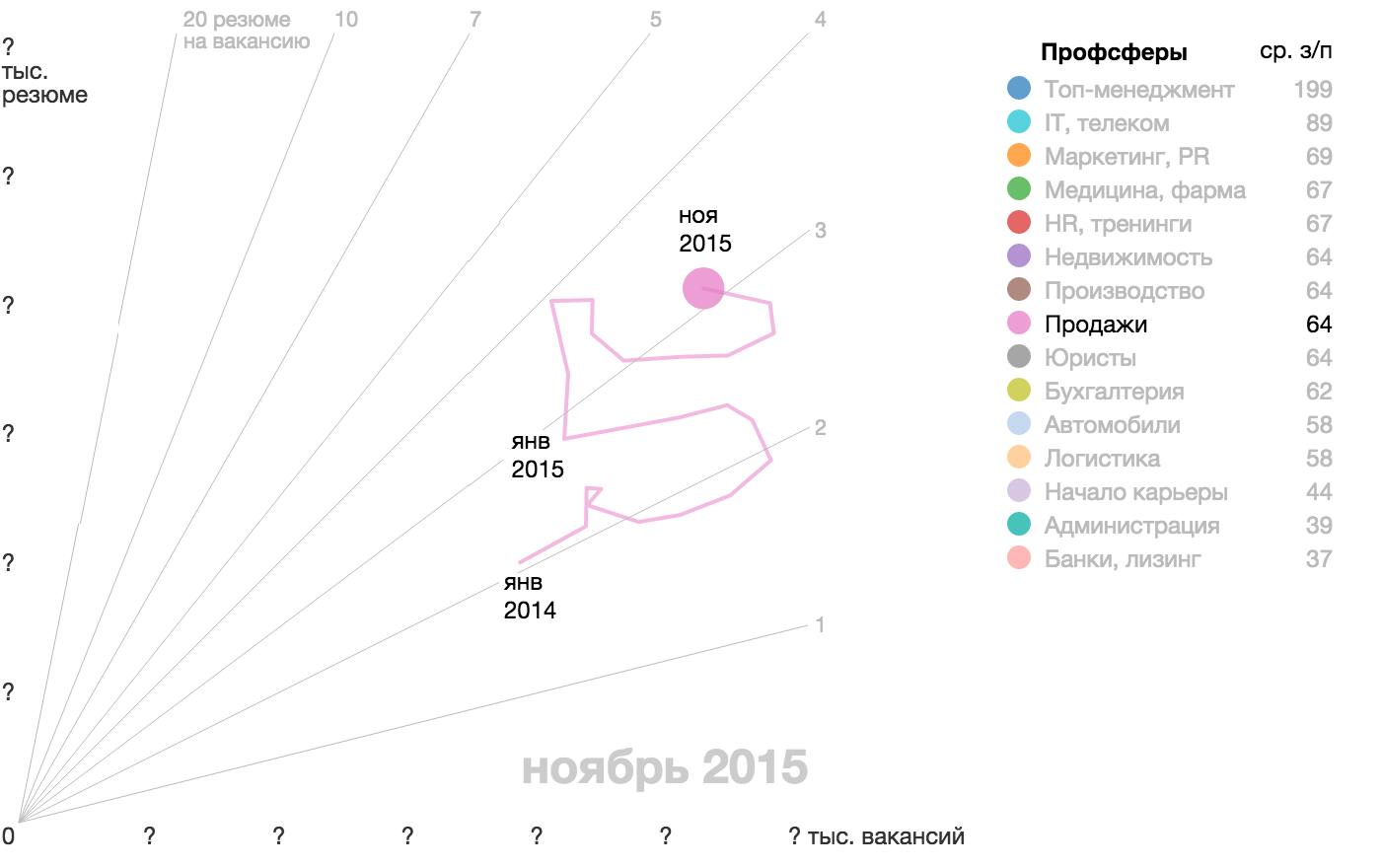
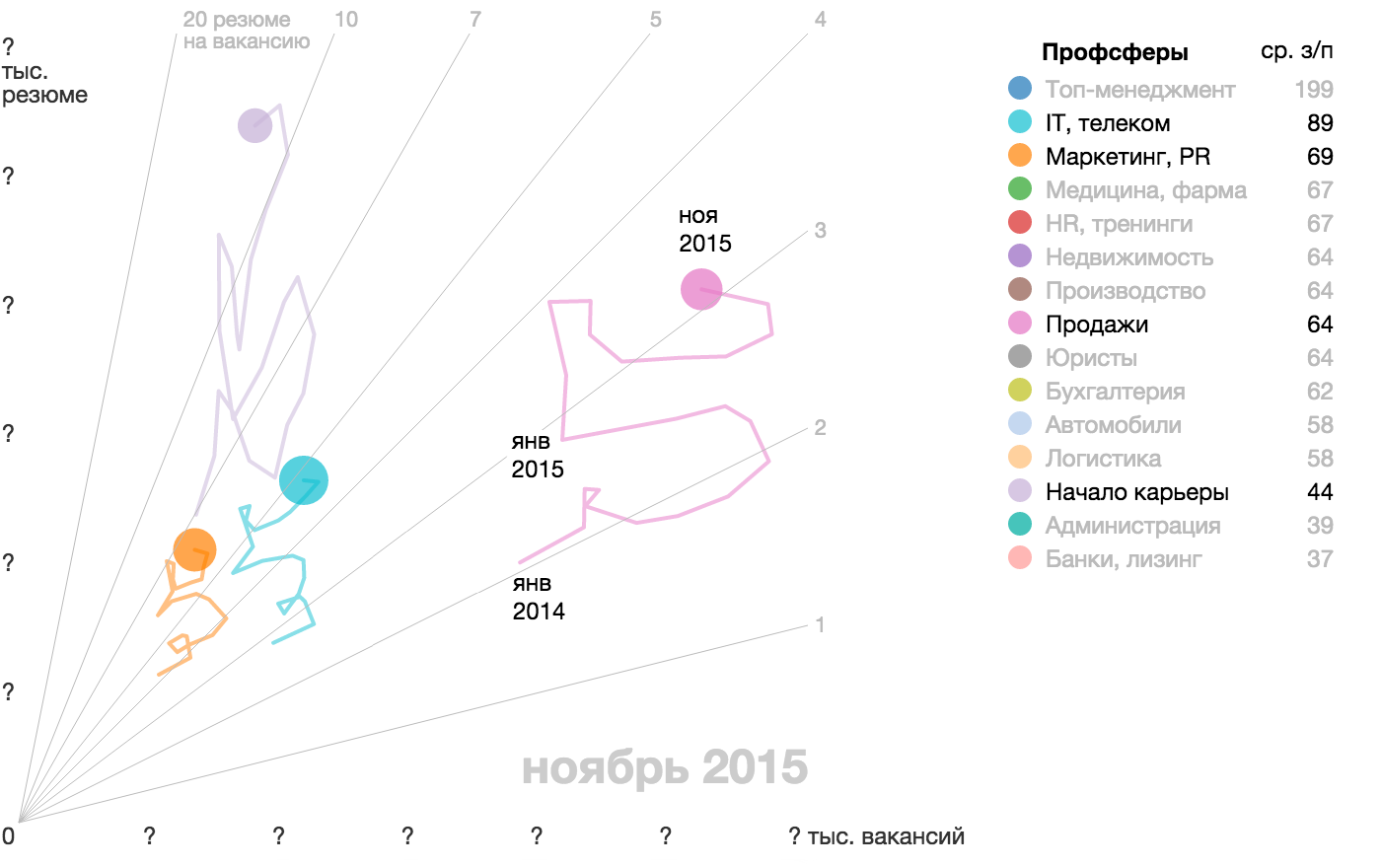



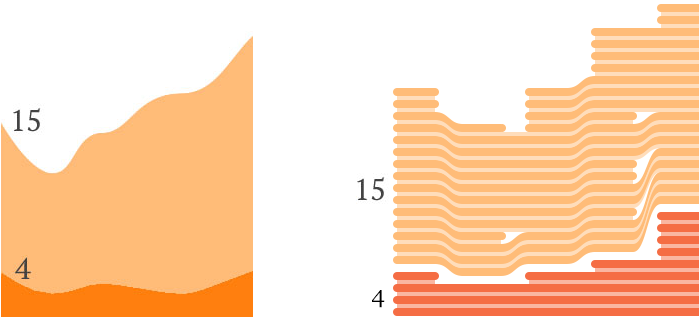

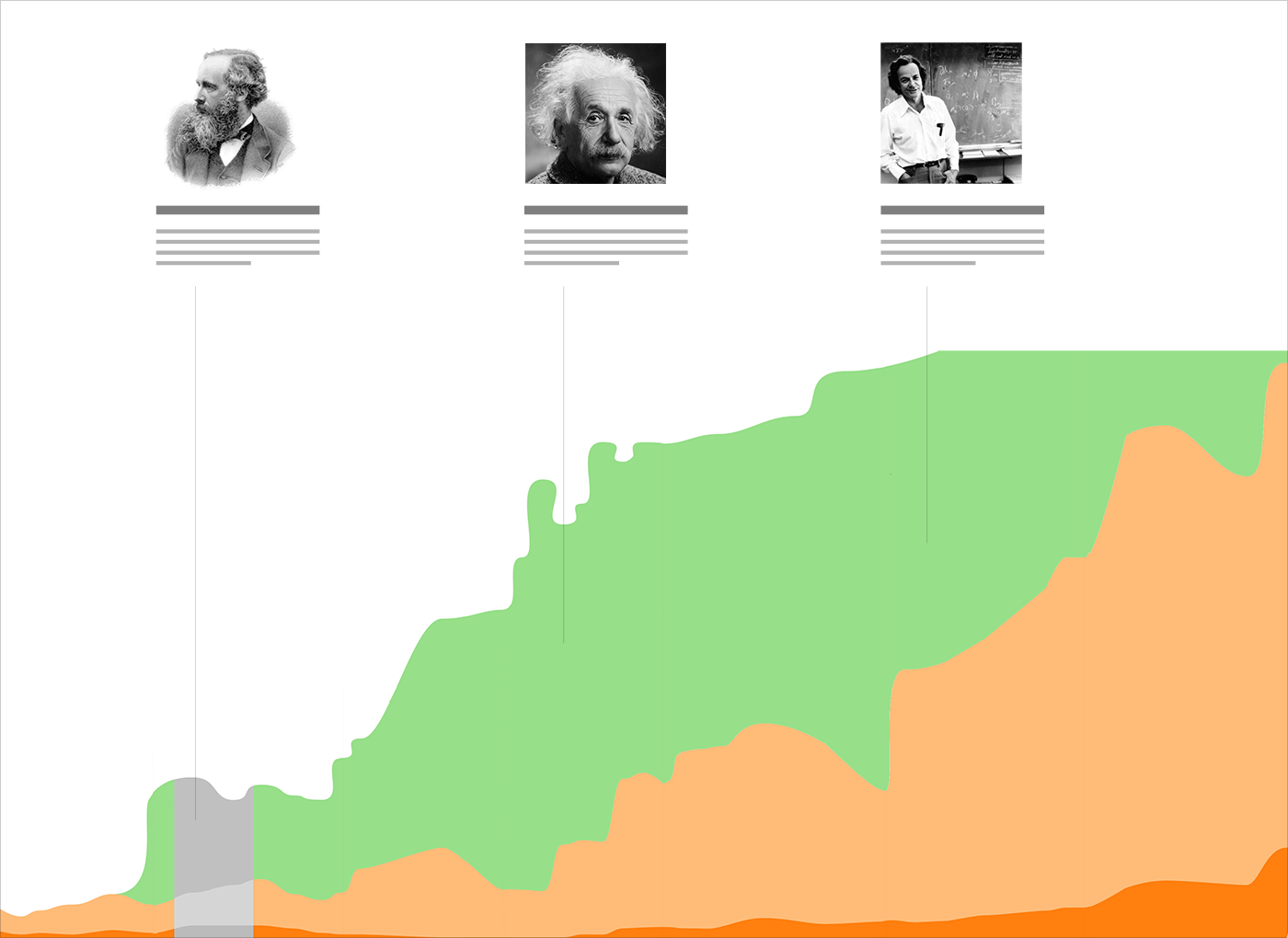
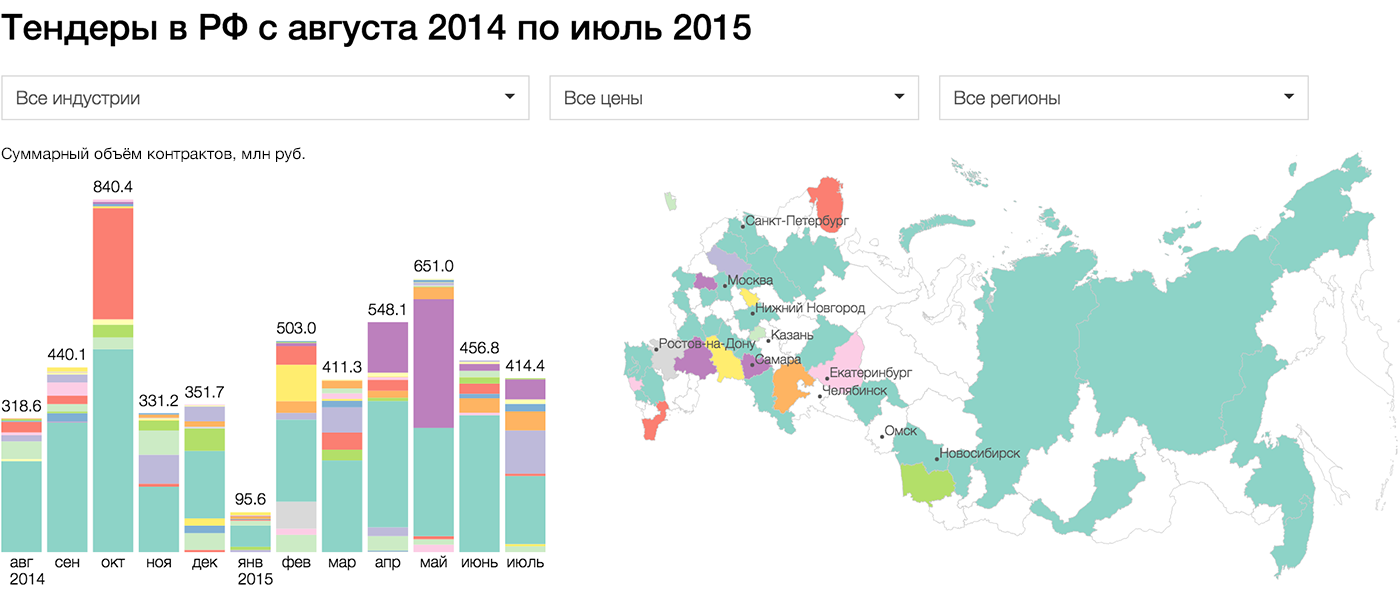
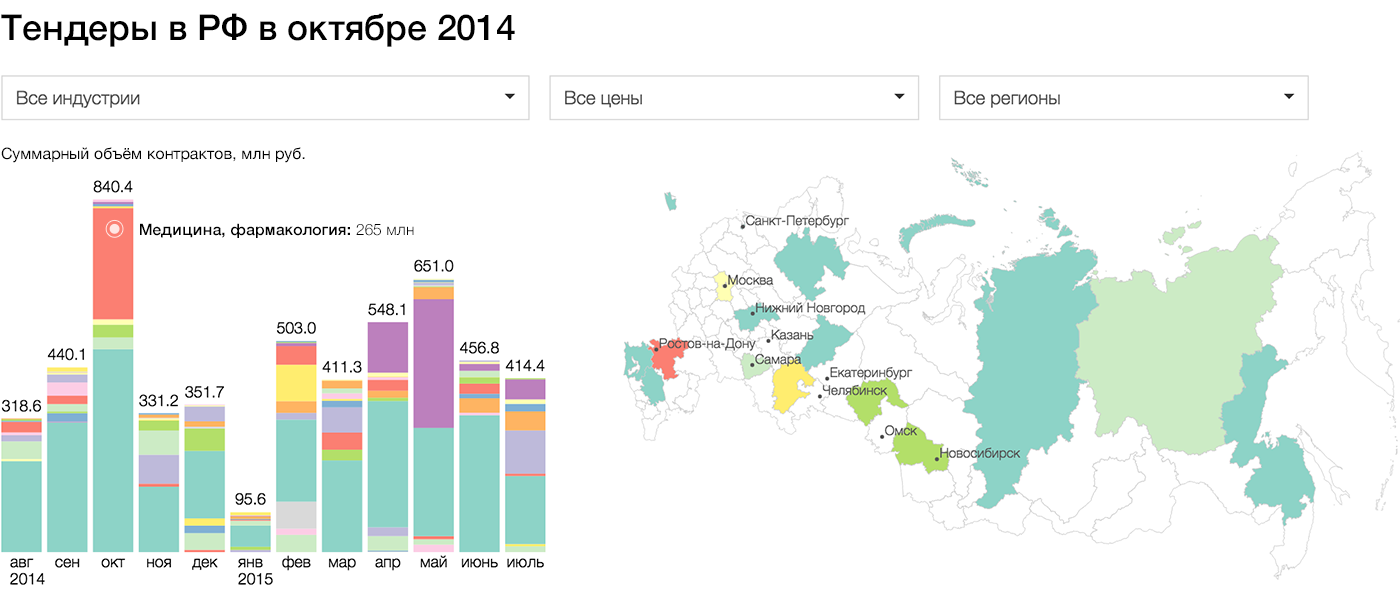
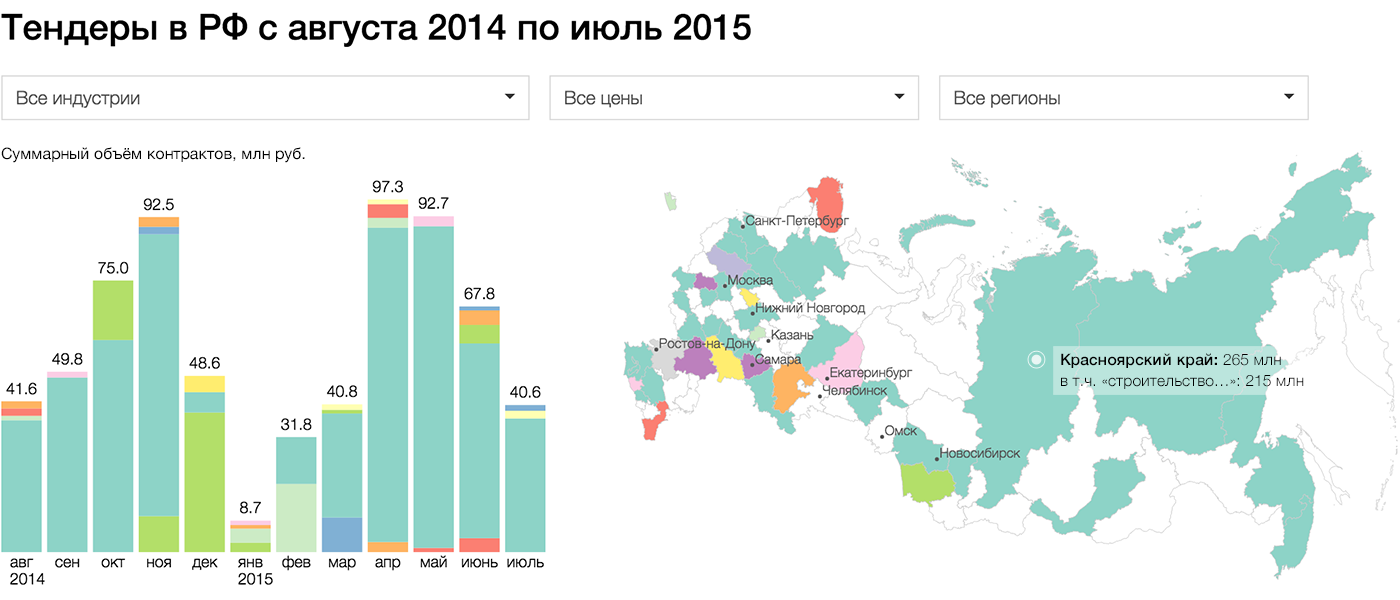
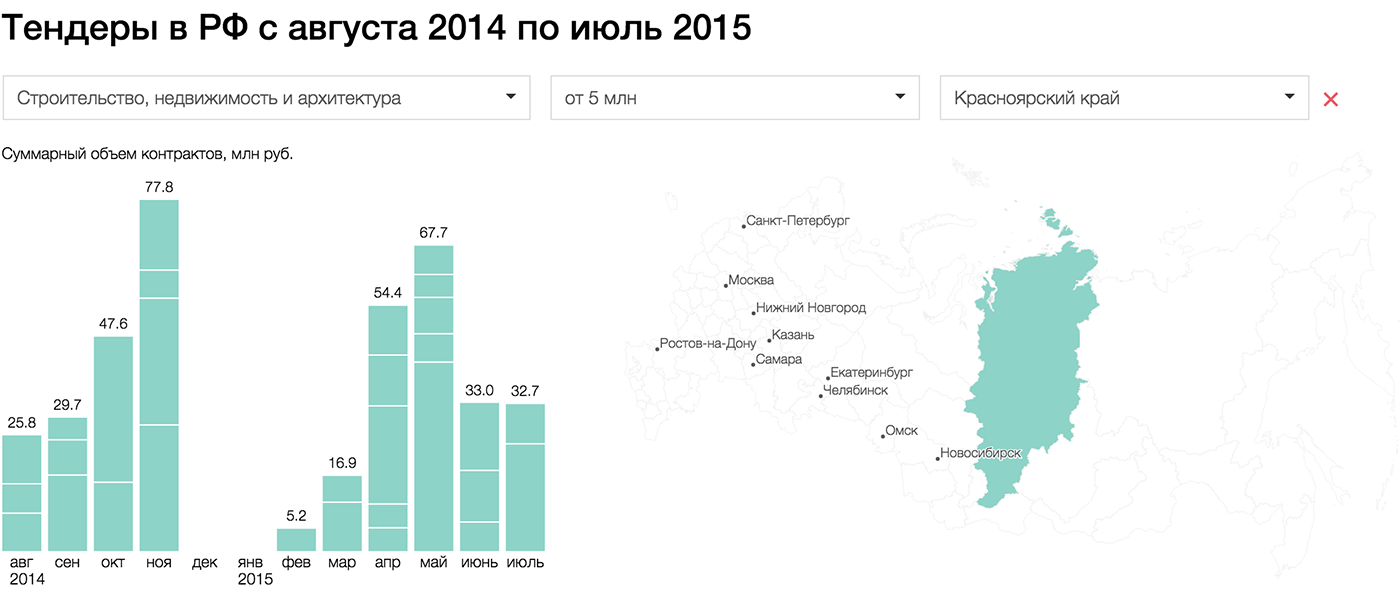
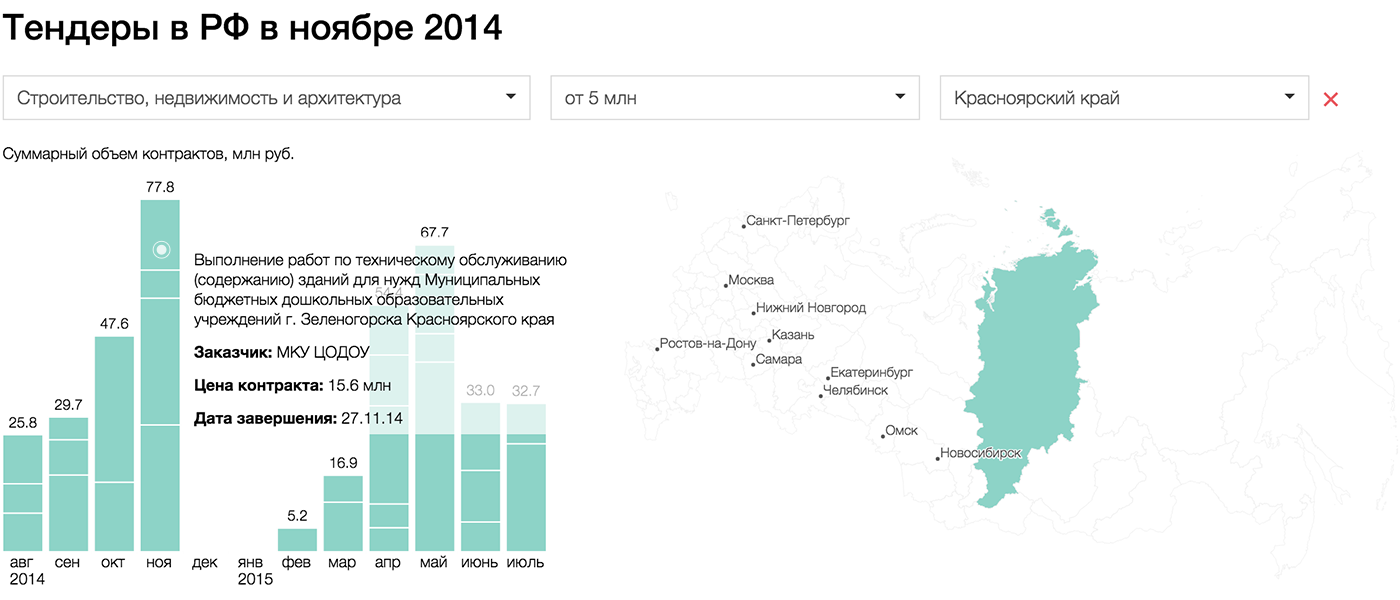
{kind=link}