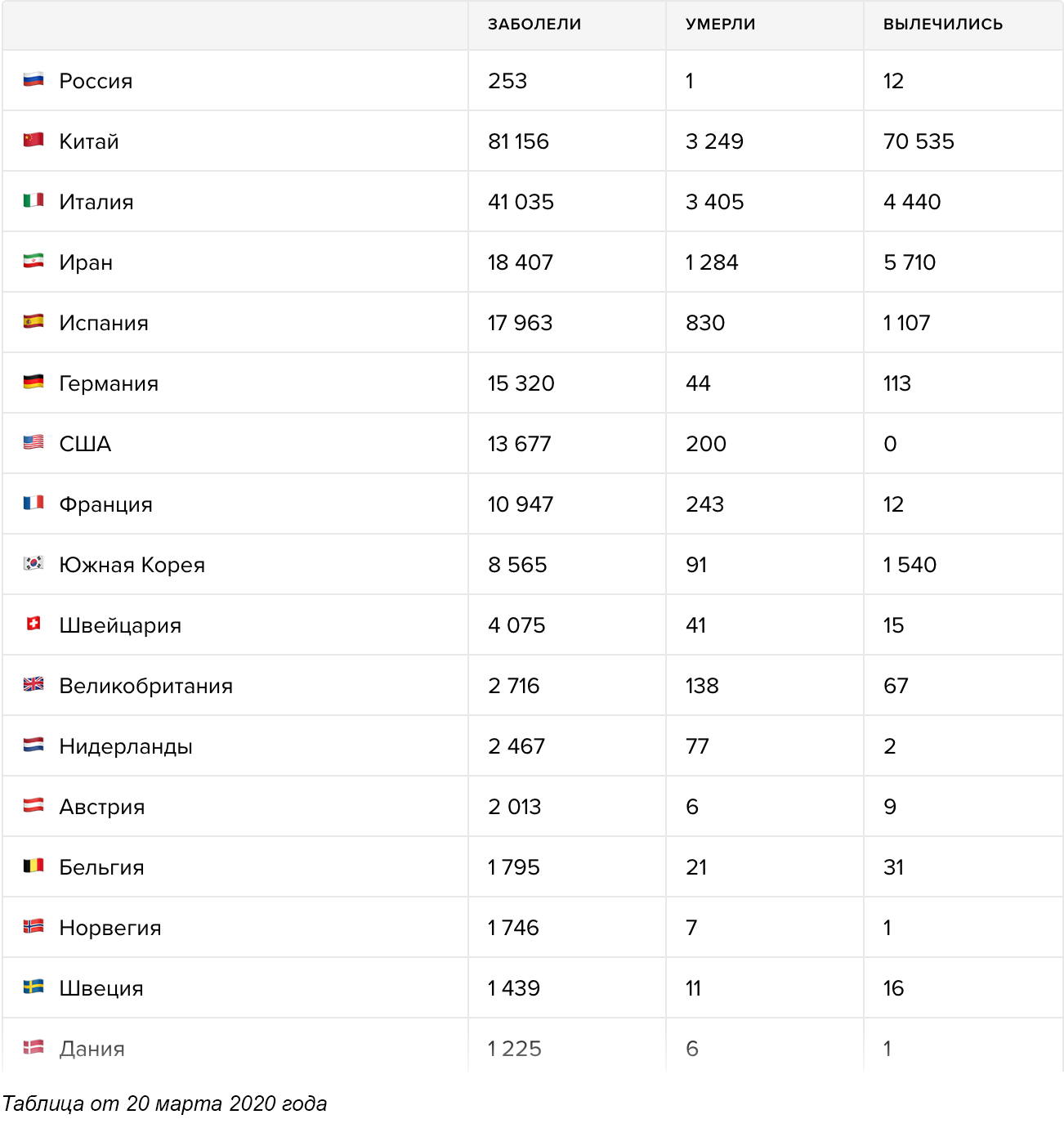
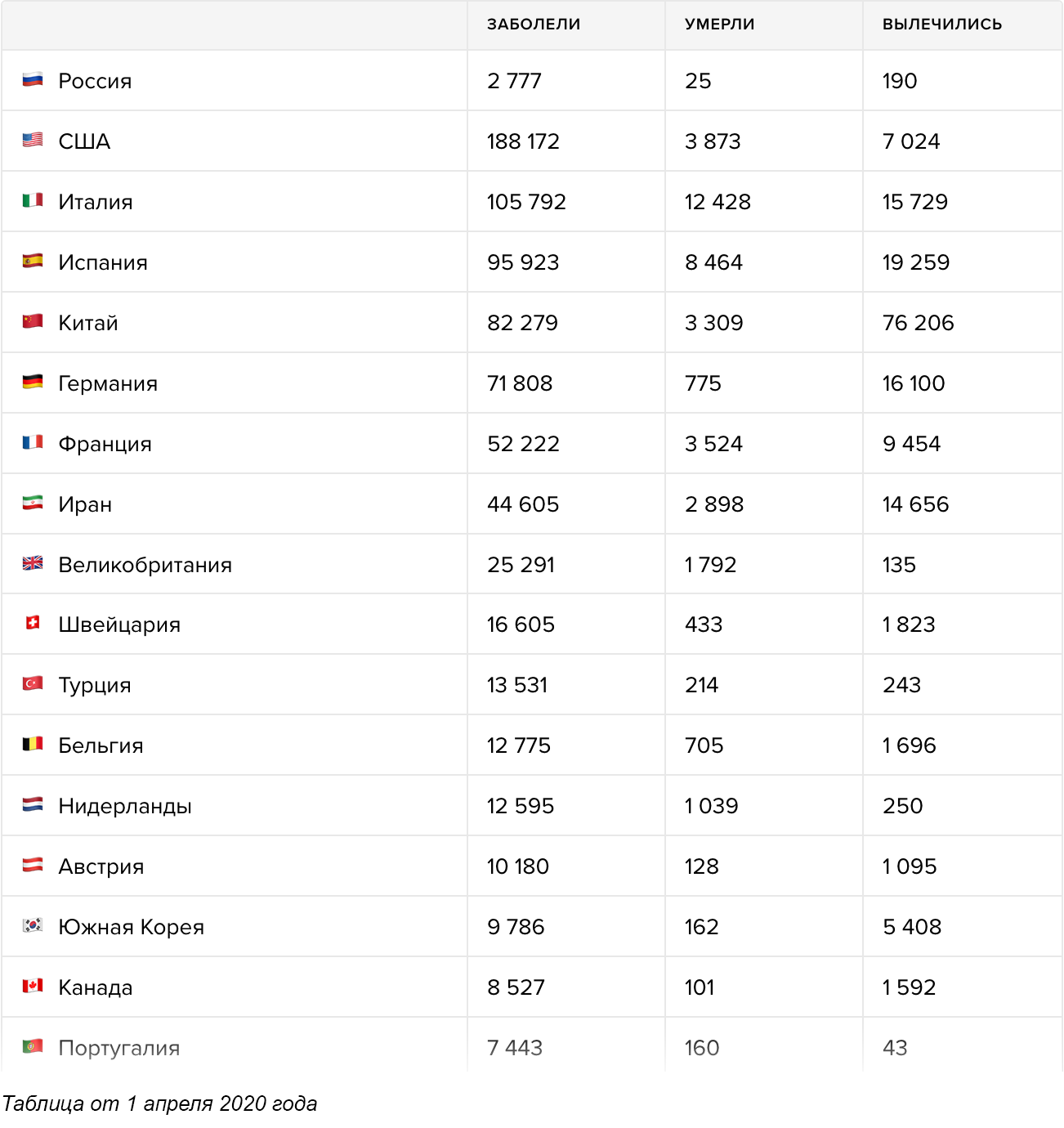
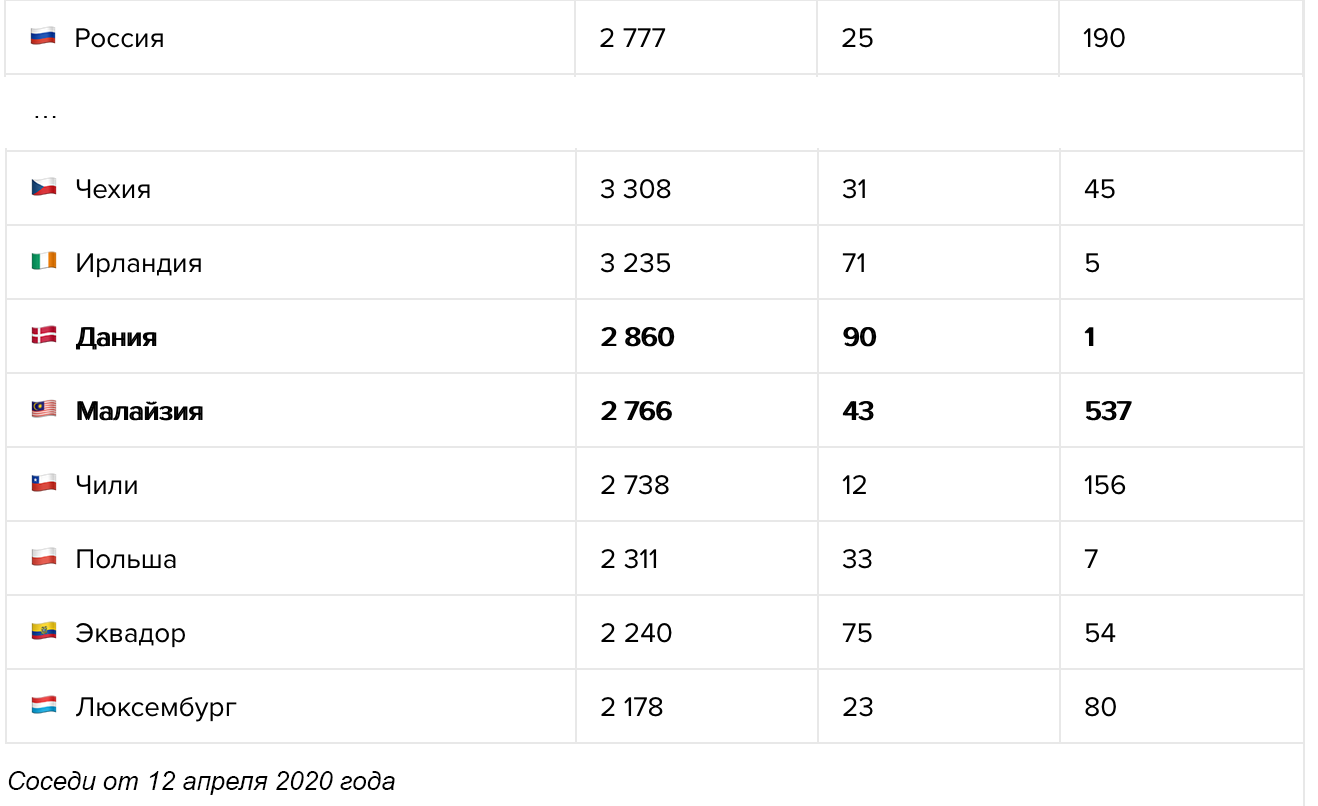
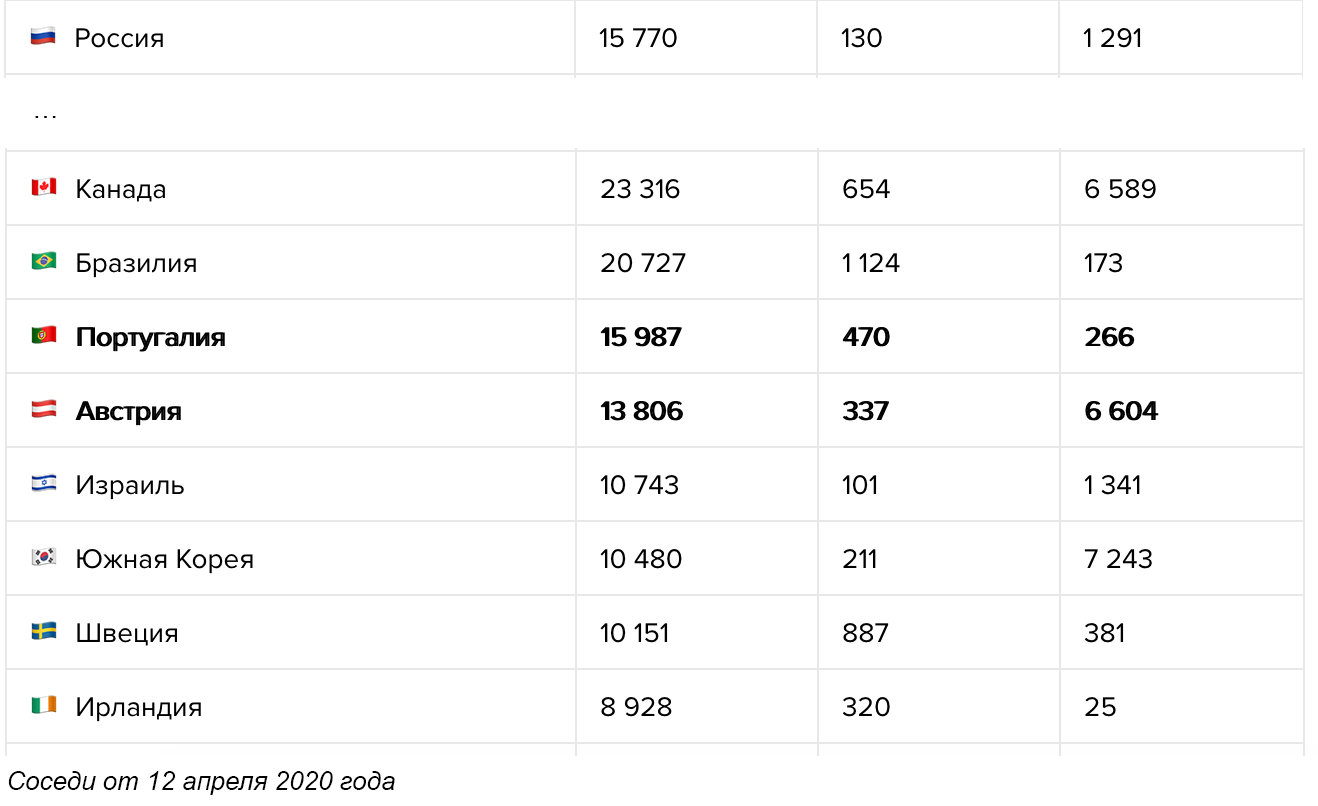
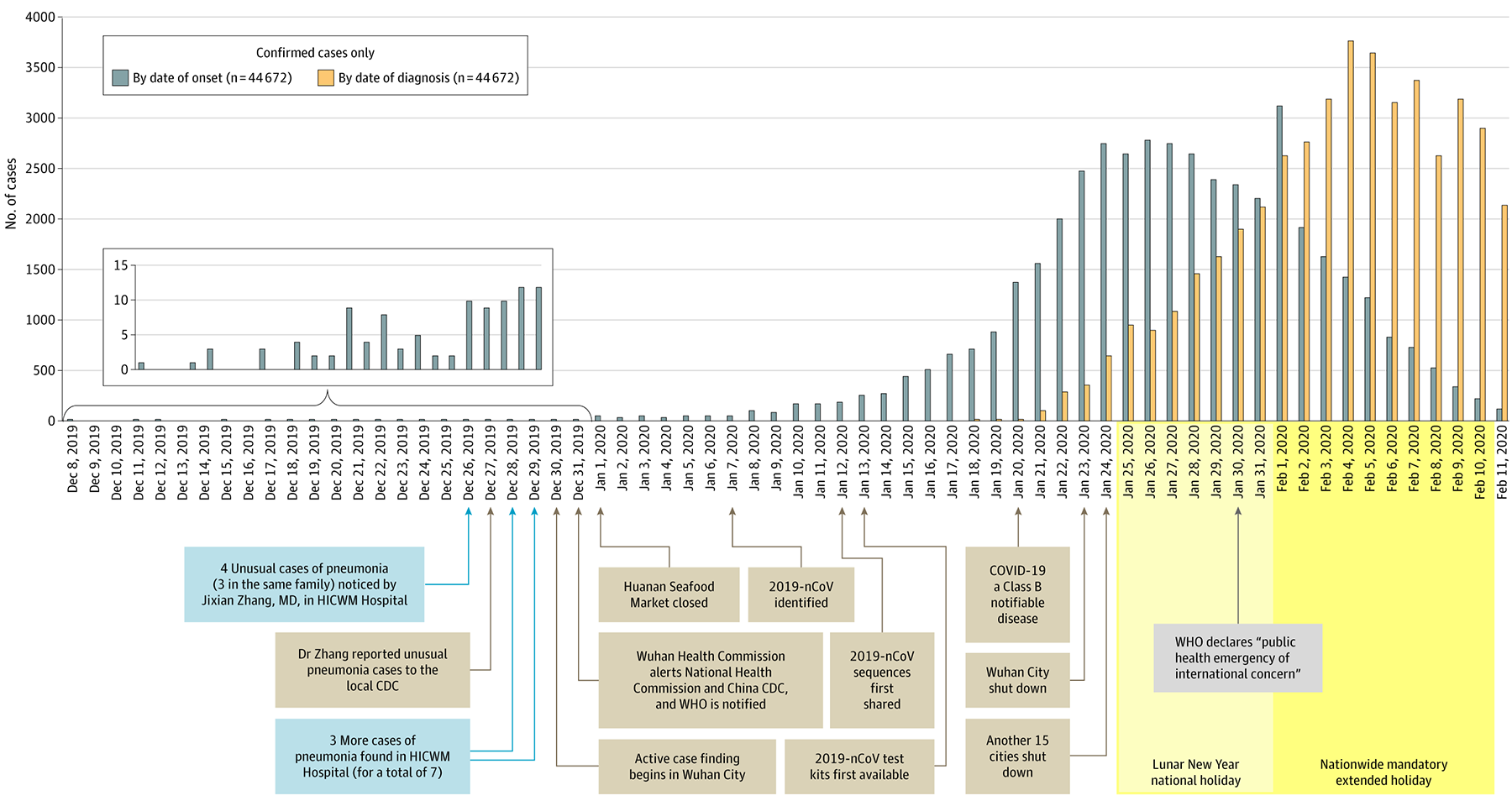
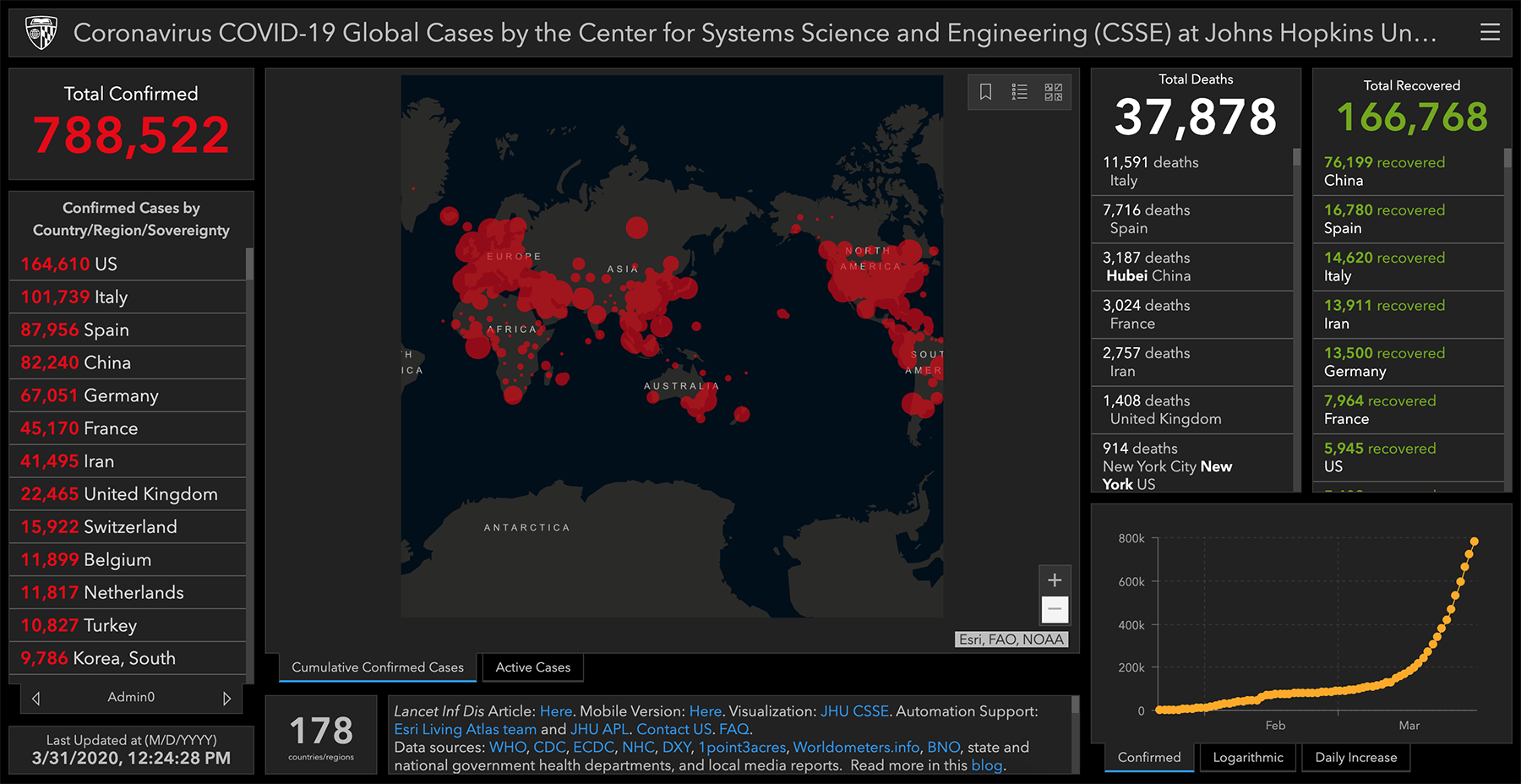
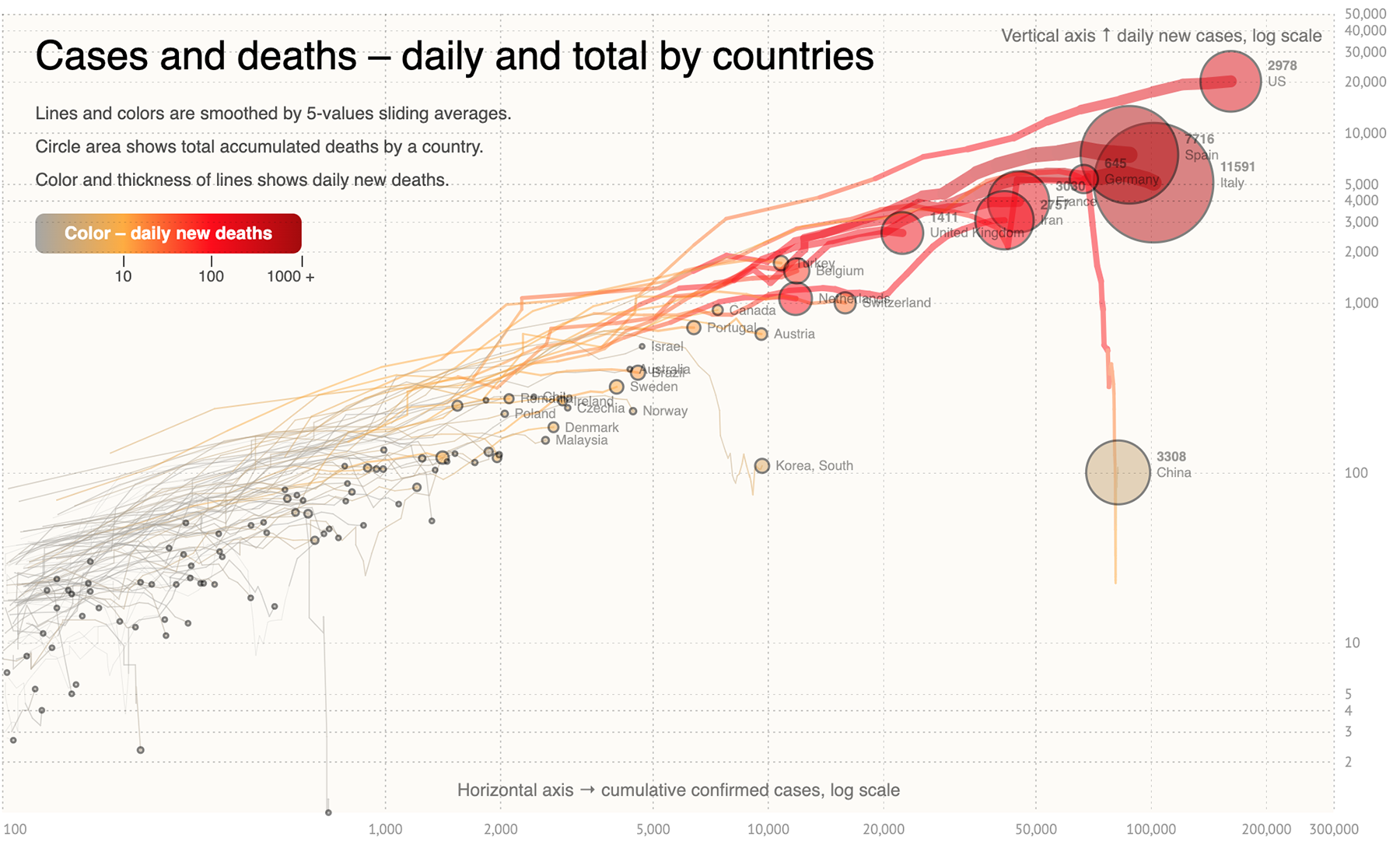
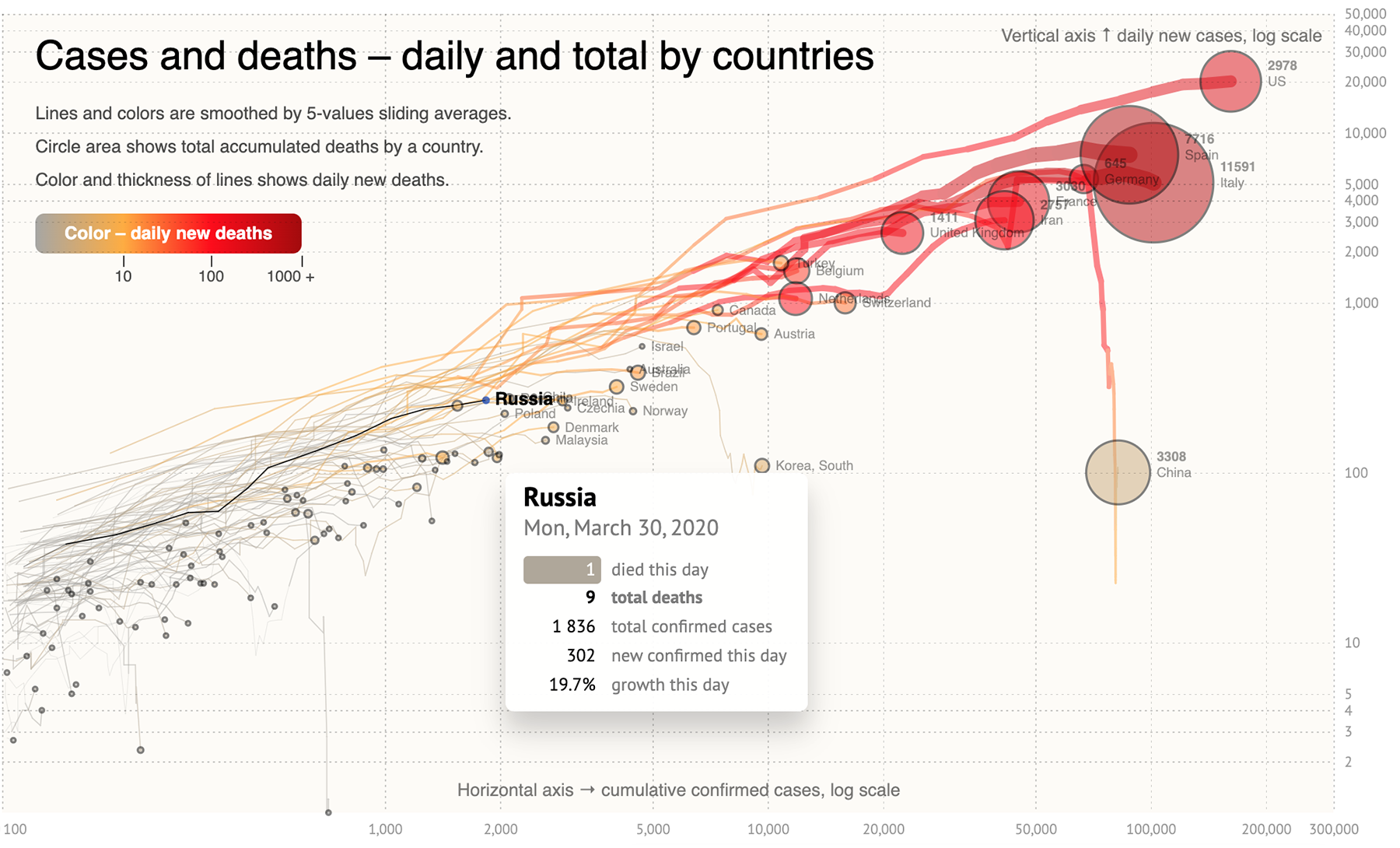
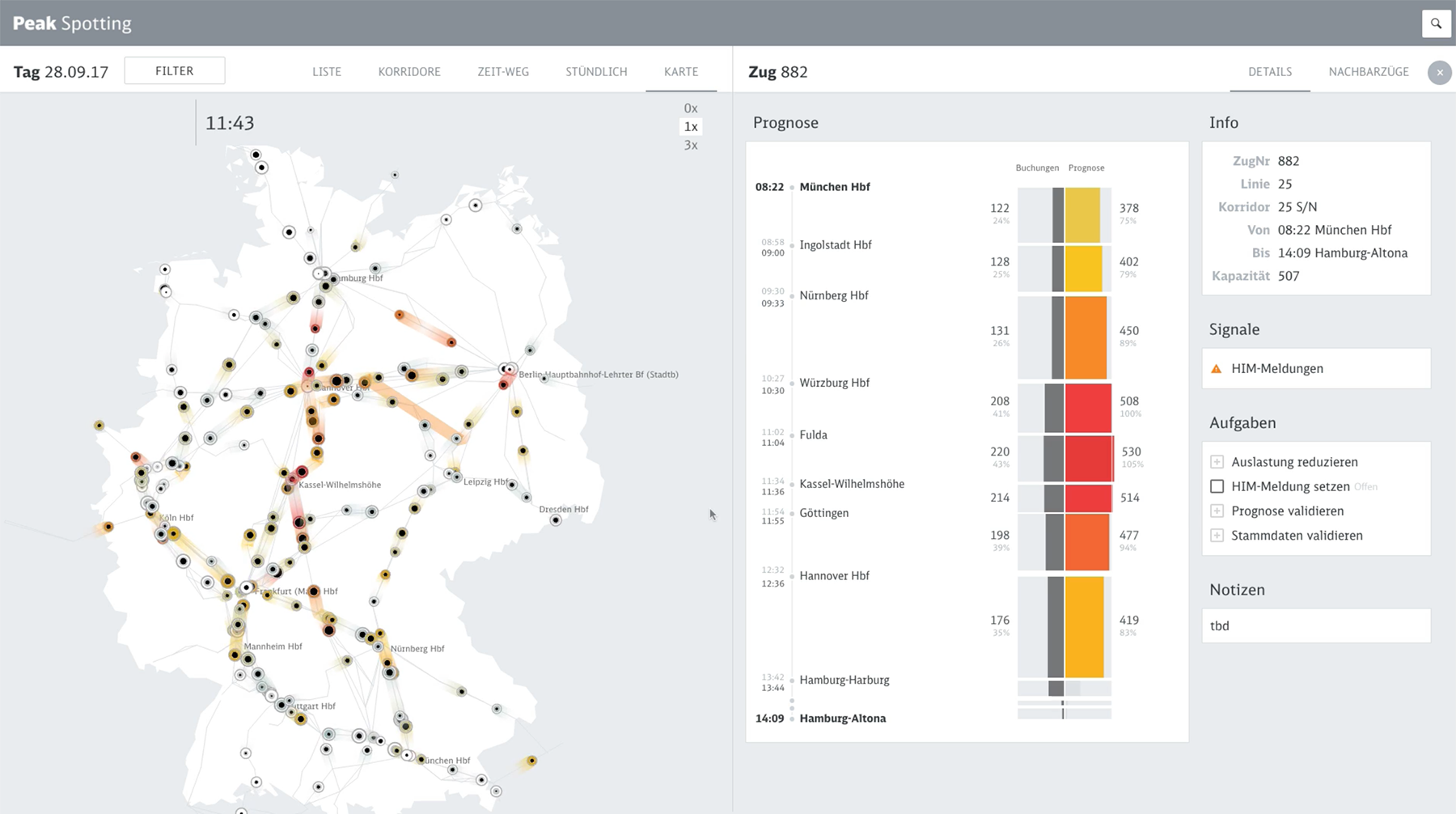
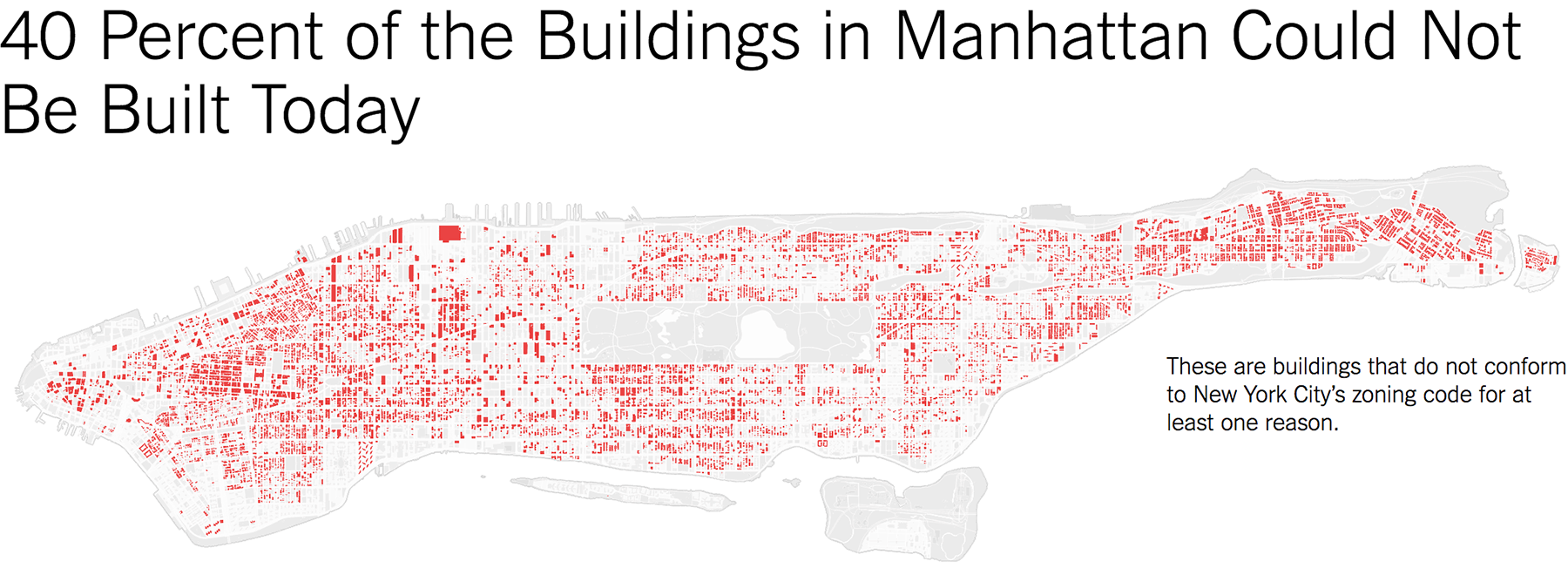
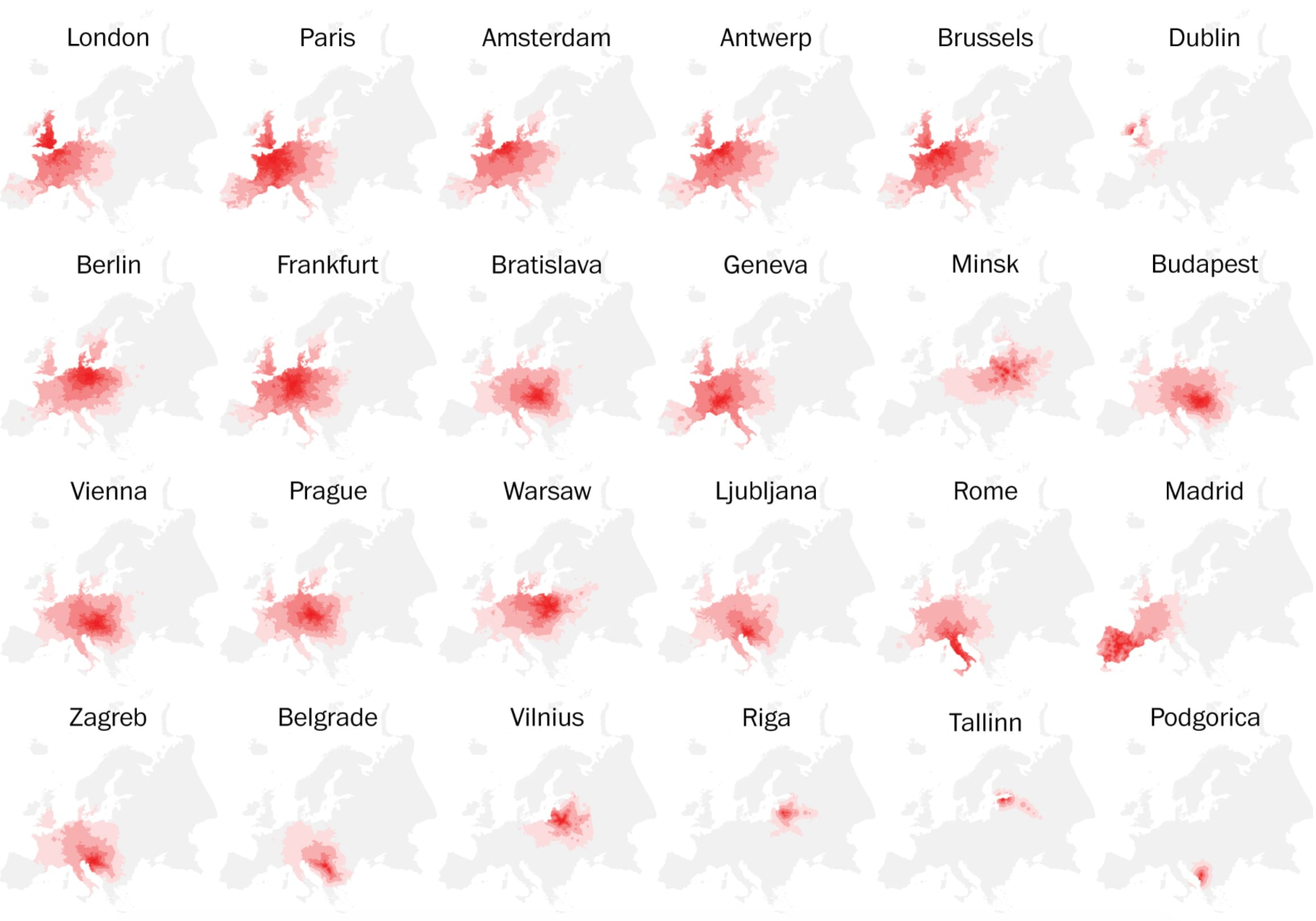
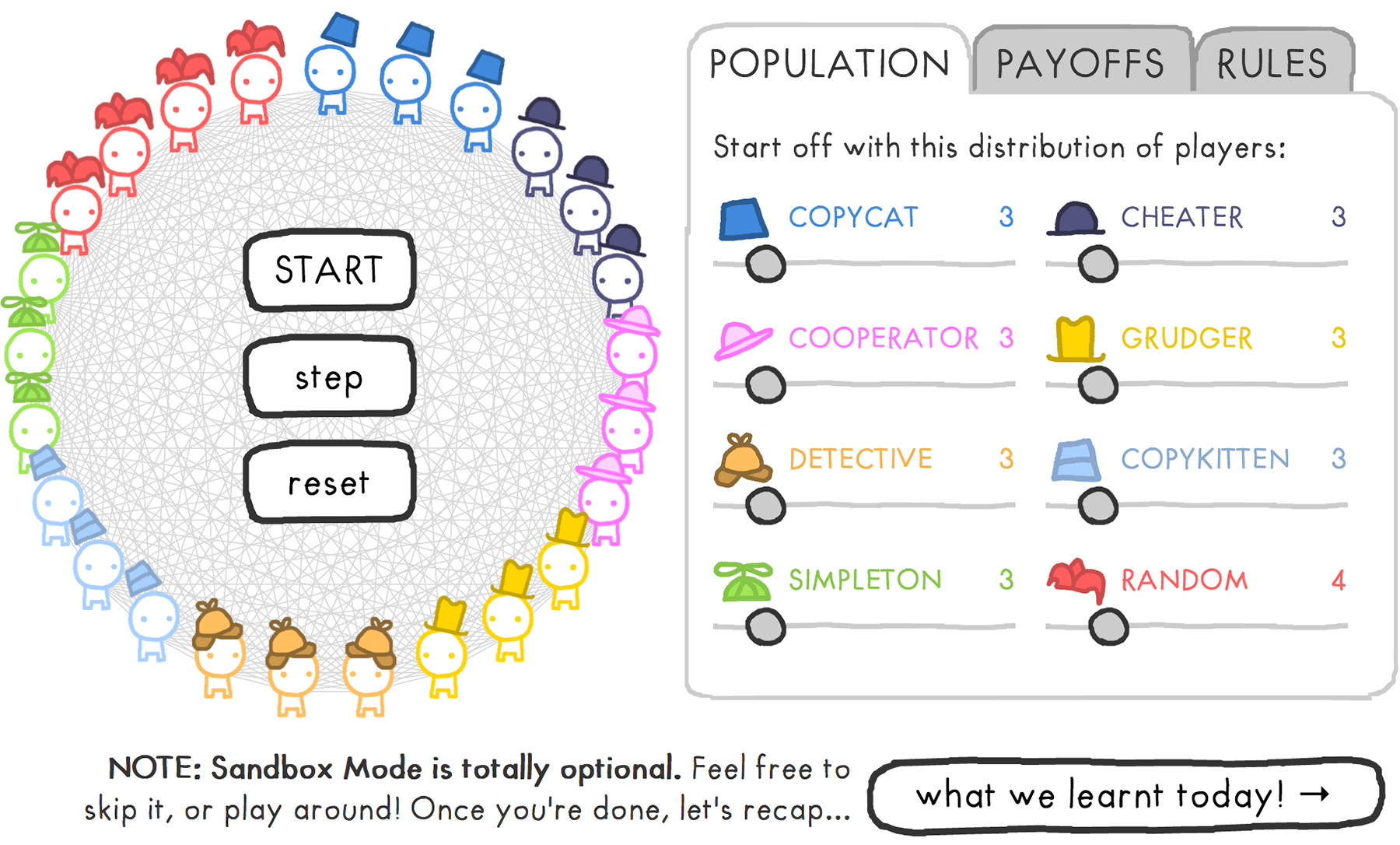
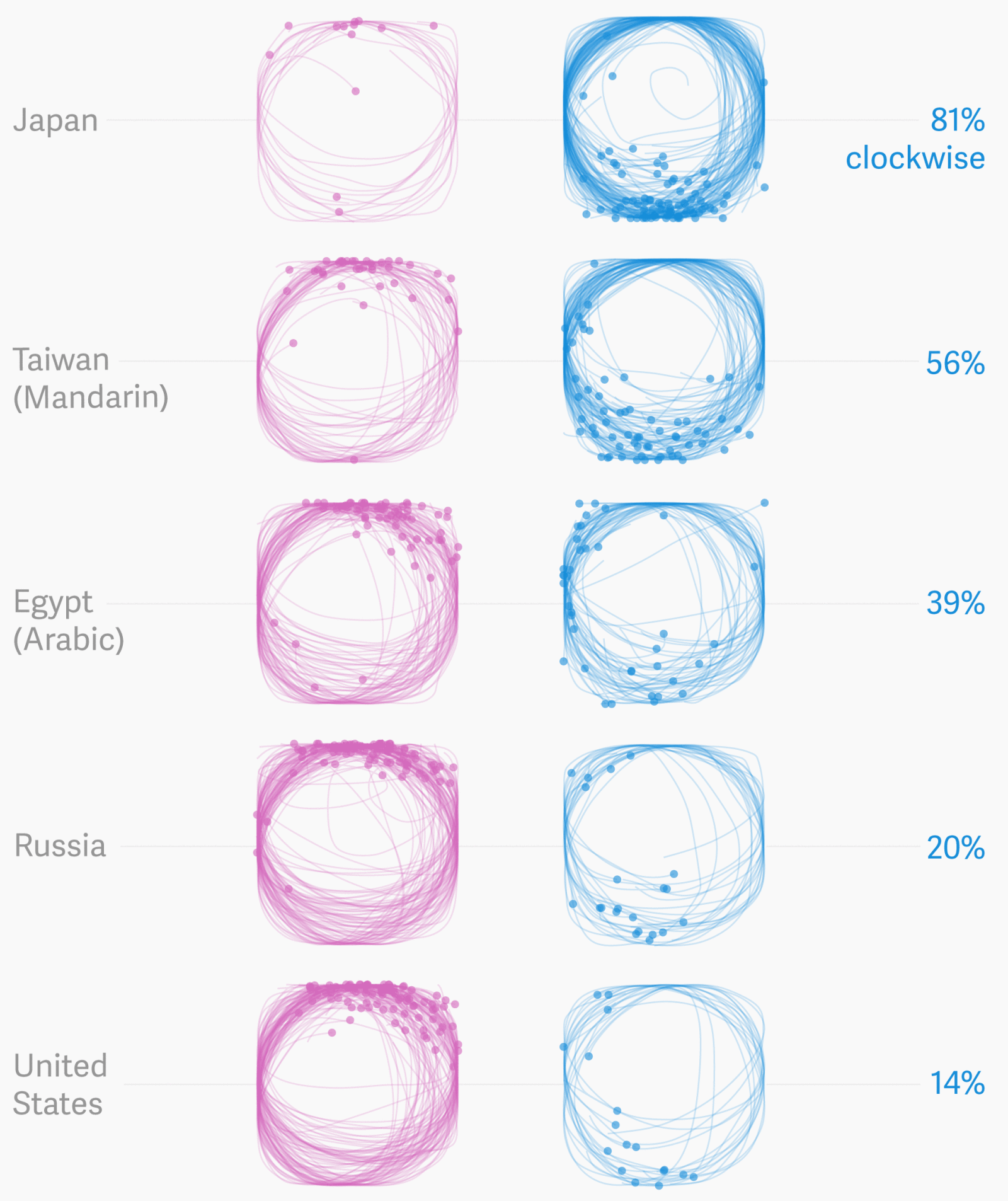
Начнём с визуализаций, посвящённых горячим новостям и острым темам 2018-го.
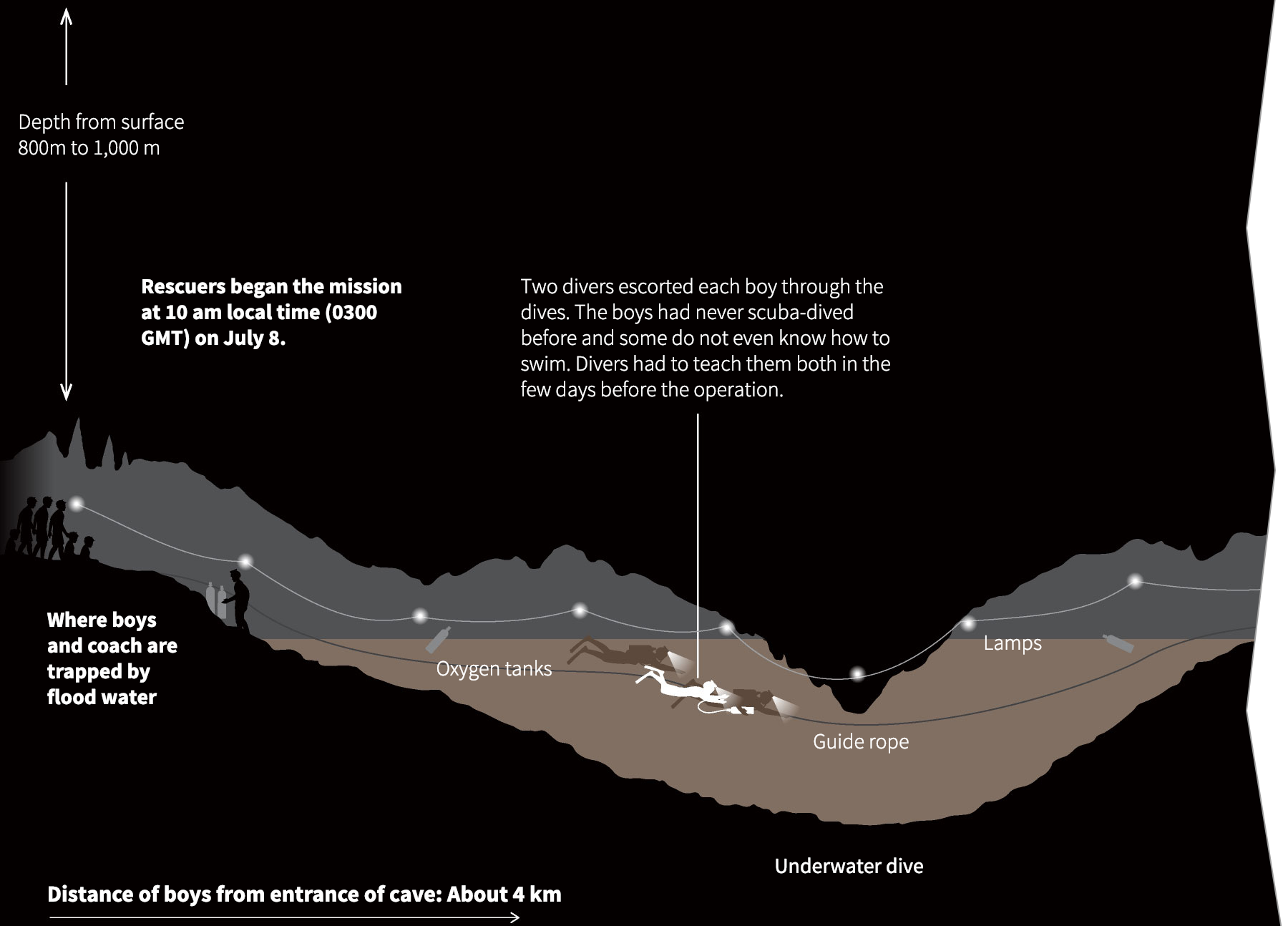
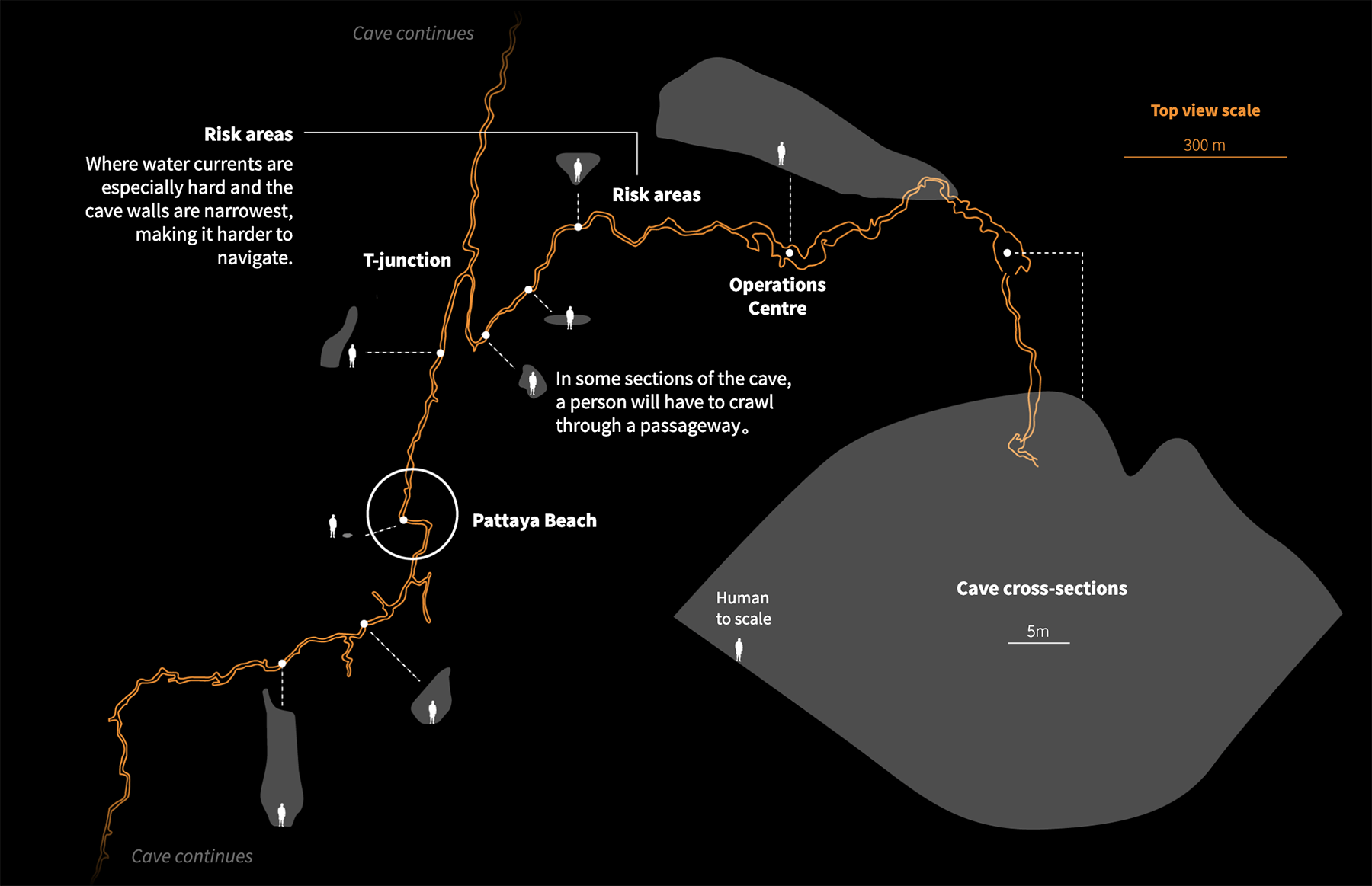
Спасательная операция в пещере Тхамлуангнангнон
Визуальные рассказы о спасении двенадцати юных футболистов и их тренера из затопленных пещер в Таиланде, опубликовали многие ведущие мировые СМИ. Мой фаворит — статья «Lucky 13» от Рейтерс. Они единственные показали маршрут спасательной операции на непрерывной схеме от начала и до конца со всеми вызовами и техническими решениями.
Там же есть понятная карта пещер с поперечным сечением в ключевых точках маршрута, включая полость под названием «Паттайя-бич», настолько узкую, что спасатели снимали кислородные баллоны, чтобы её преодолеть.
Другие достойные внимания визуальные истории на эту тему: Нью-йорк-таймс, Гардиан, Саус-чайна-пост.
Природные катастрофы
В мае на самом большом из гавайских островов произошло необычное — газовое или фреатрическое — извержение вулкана Килауэа, а также открылись трещины в жилом районе Леилани-Эстейтс, через которые вытекала лава. Хороший материал об этом — в Вашингтон-пост. Там и изящные карты, и наглядная схема-объяснение механизма извержения, и временная развёртка упавшего уровня лавы в лавовом озере кратера Халемаумау, и захватывающее видео фонтанов лавы, и самая красноречивая, на мой взгляд, визуализация — вот это изображение извергающейся трещины в тихом жилом квартале на пересечении улиц Лауны и Леилани:
В мае Нью-йорк-таймс проанализировало регионы, наиболее подверженные природным катастрофам:
В сентябре они же опубликовали завораживающую визуализацию урагана Флоренс:
А в ноябре — рассказ о лесном пожаре, уничтожившем городок Парадайз в Калифорнии:
На этой визуализации удачно подружились пространственное и временное измерение, и очень эффектно работает скролл (см. оригинал).
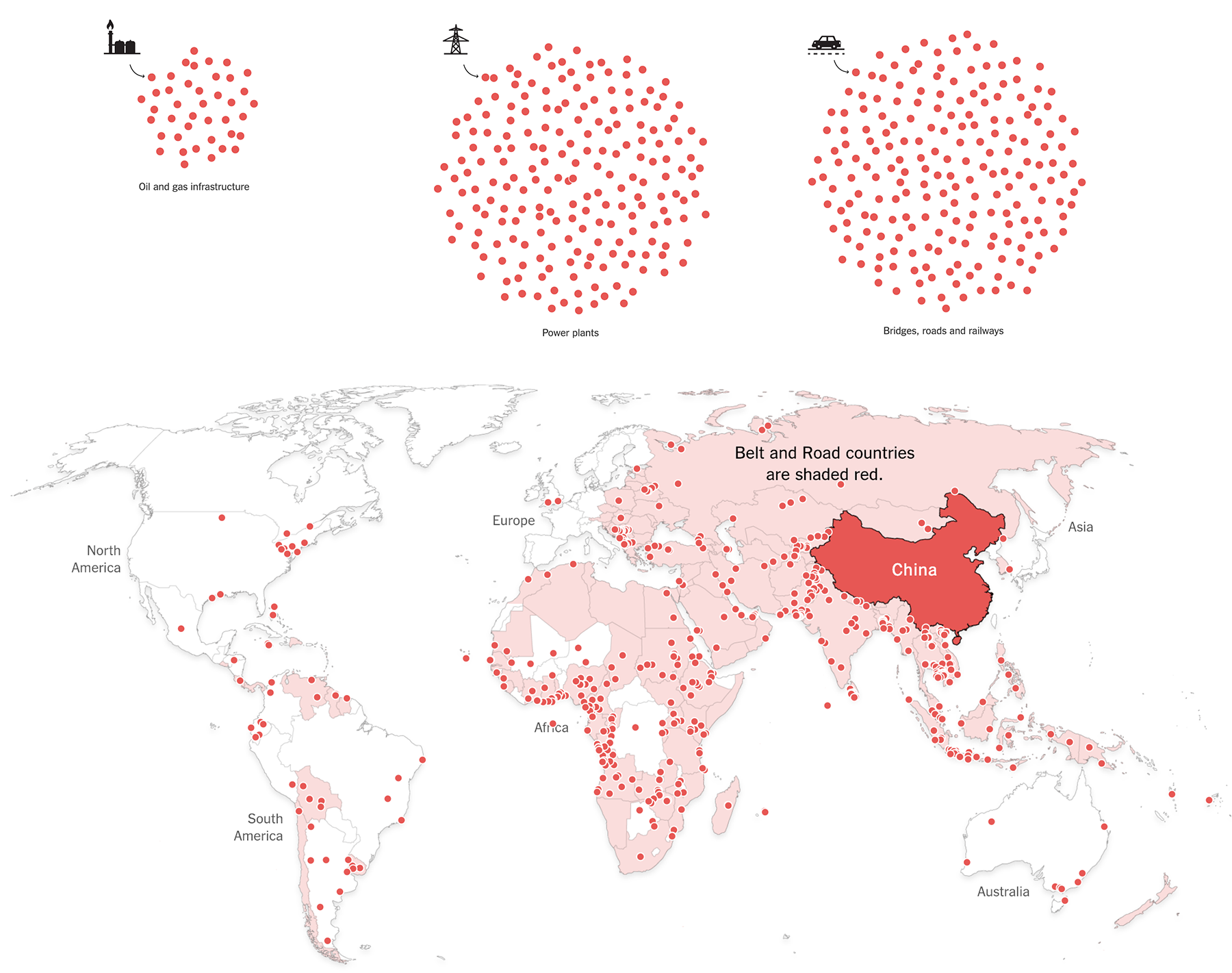
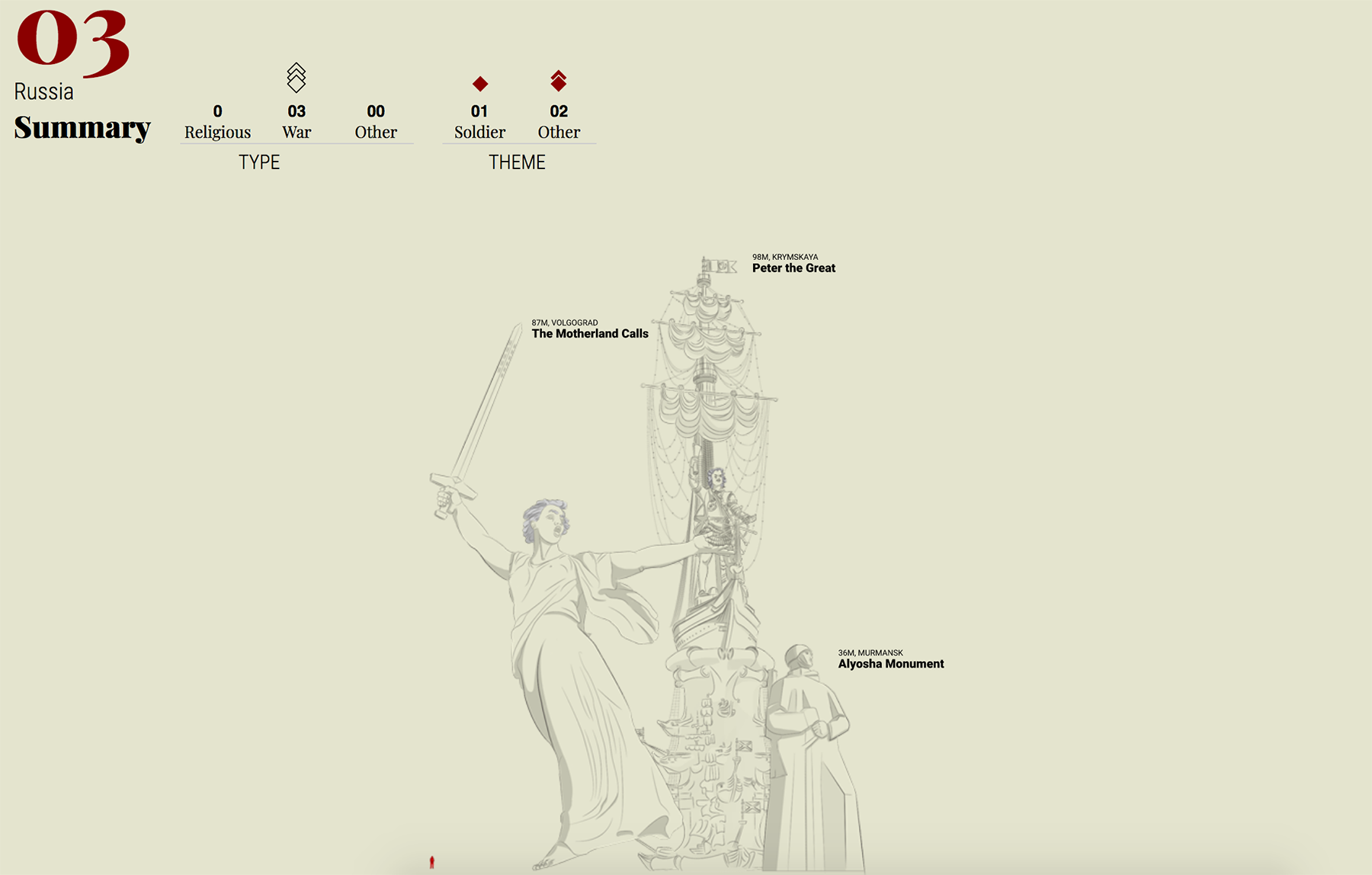
Китай
В 2018-м Китай продолжал строить дороги, мосты, дамбы, газо- и нефте-проводовы, тепло-, гидро- и атомные электростанции по всему миру. Нью-йорк-таймс, Гардиан, Блумберг и другие издания визуализируют масштабы строительства, анализируют стратегические цели Китая и проблему «долговой ловушки», в которой оказываются страны-партнёры.
Журналисты Рейтерс опубликовали визуальное расследование вокруг объектов, которые предположительно являются китайскими лагерями для заключённых-мусульман. В статье «Tracking China’s Muslim Gulag» они анализируют снимки со спутника и фотографии объектов и делают выводы об увеличении как количества лагерей, так и их размеров. Выводы подкреплены убедительной и интересной графикой:
Здесь же классный приём — обход периметра по скроллу:
Саус-чайна-морнинг-пост разбавляет китайскую тему материалом о богатых азиатах с серией визуализаций разной степени серьёзности:
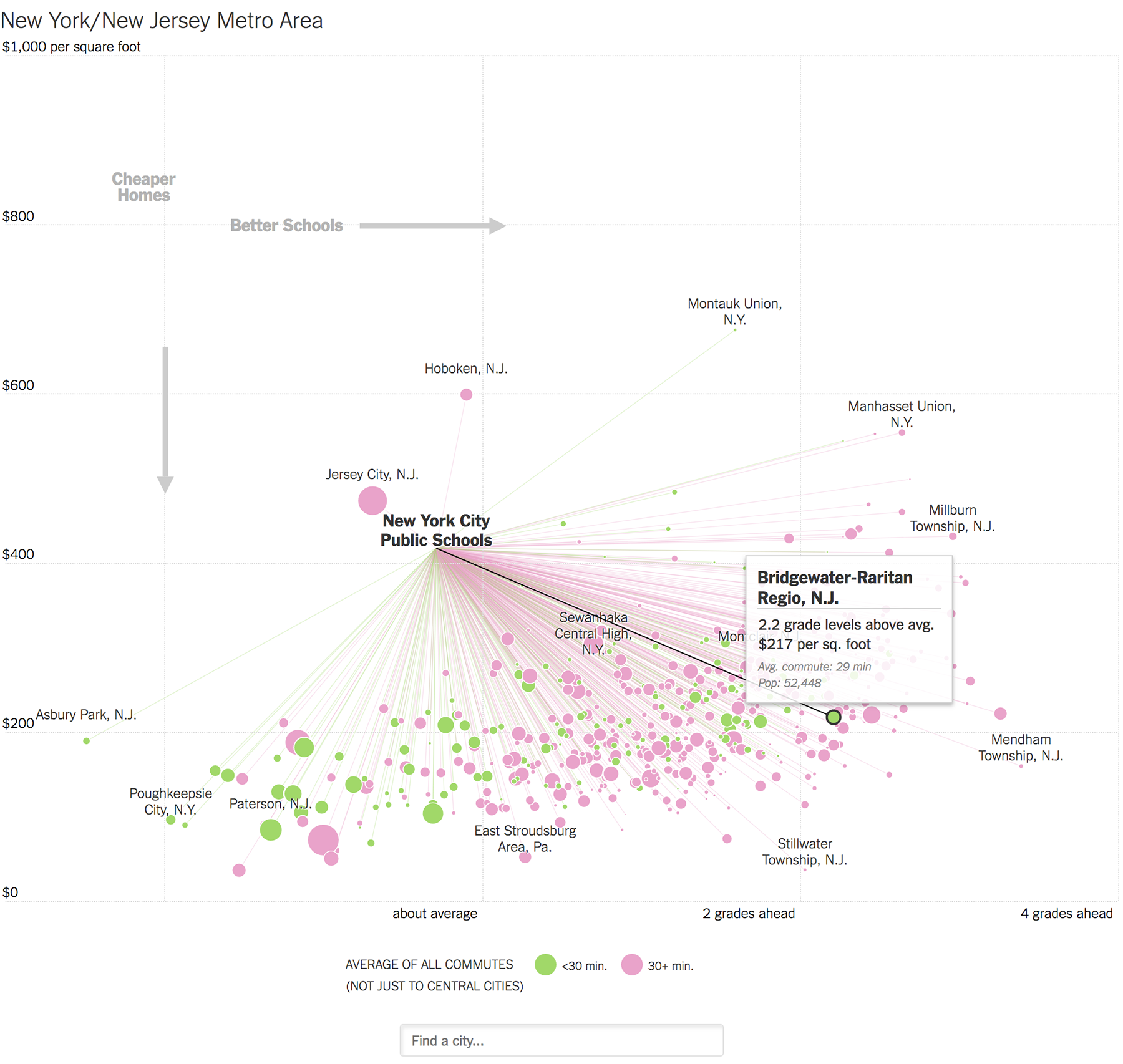
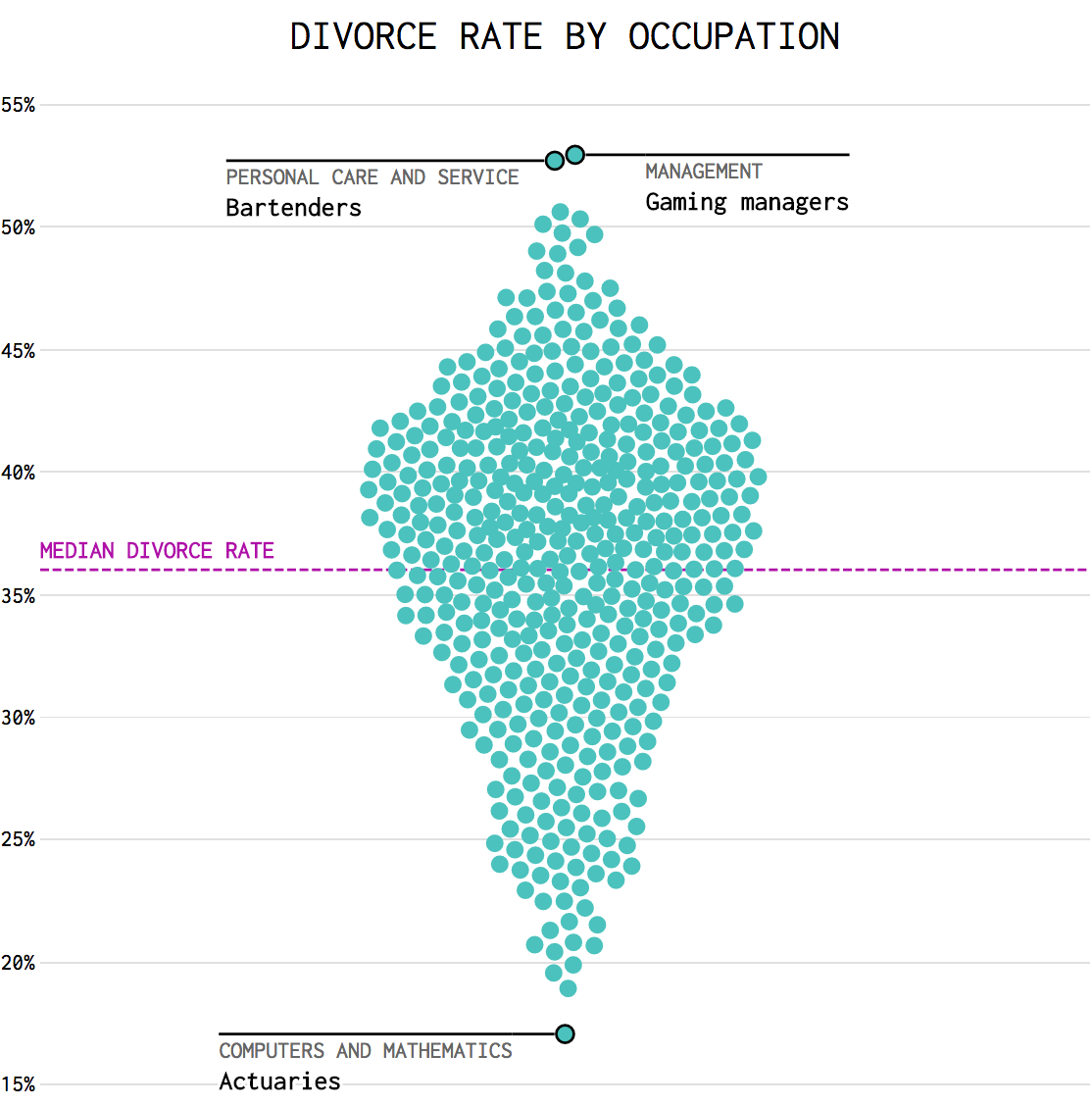
Деньги и общество
Гениальная в своей простоте визуализация использования земли в США:
Разбив карту на маленькие квадраты и сгруппировав их по назначению земли внутри самой карты, авторы добились метафоры, понятной любому американскому школьнику. Будь-то леса, пастбища или сельскохозяйственные угодия, все эти территории теперь можно «измерить» в штатах. Интересно было бы взглянуть на аналогичную визуализацию о родных просторах.
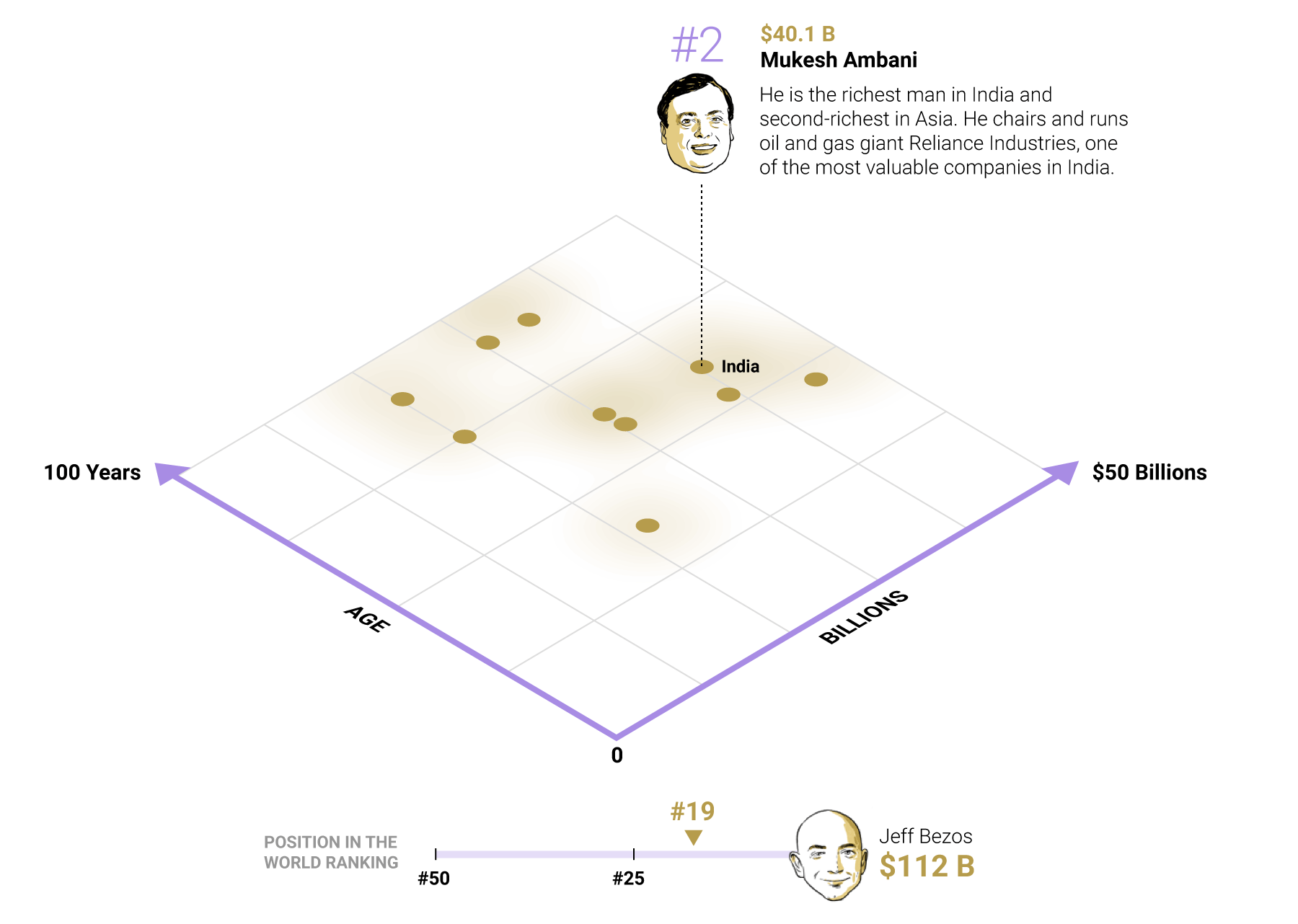
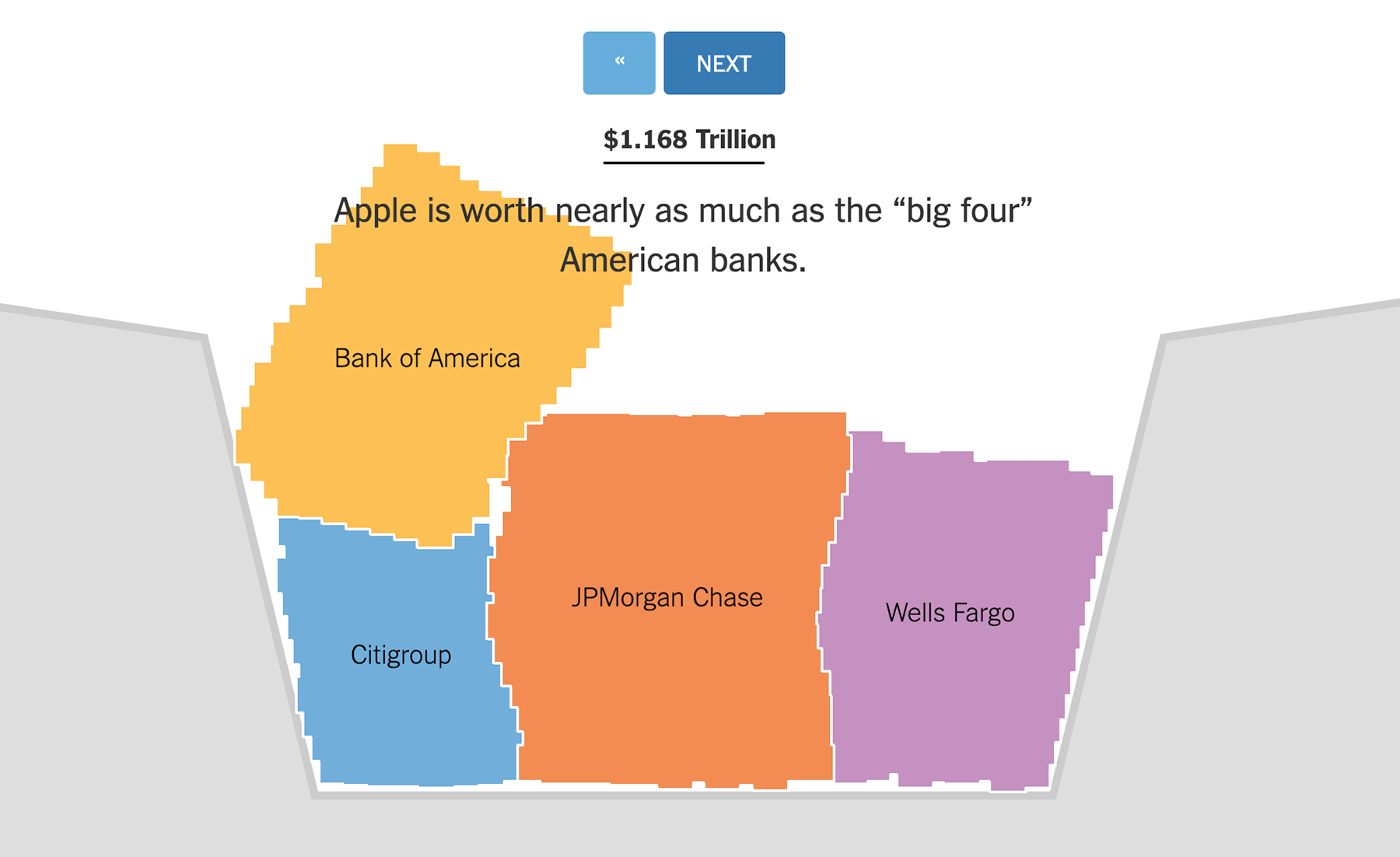
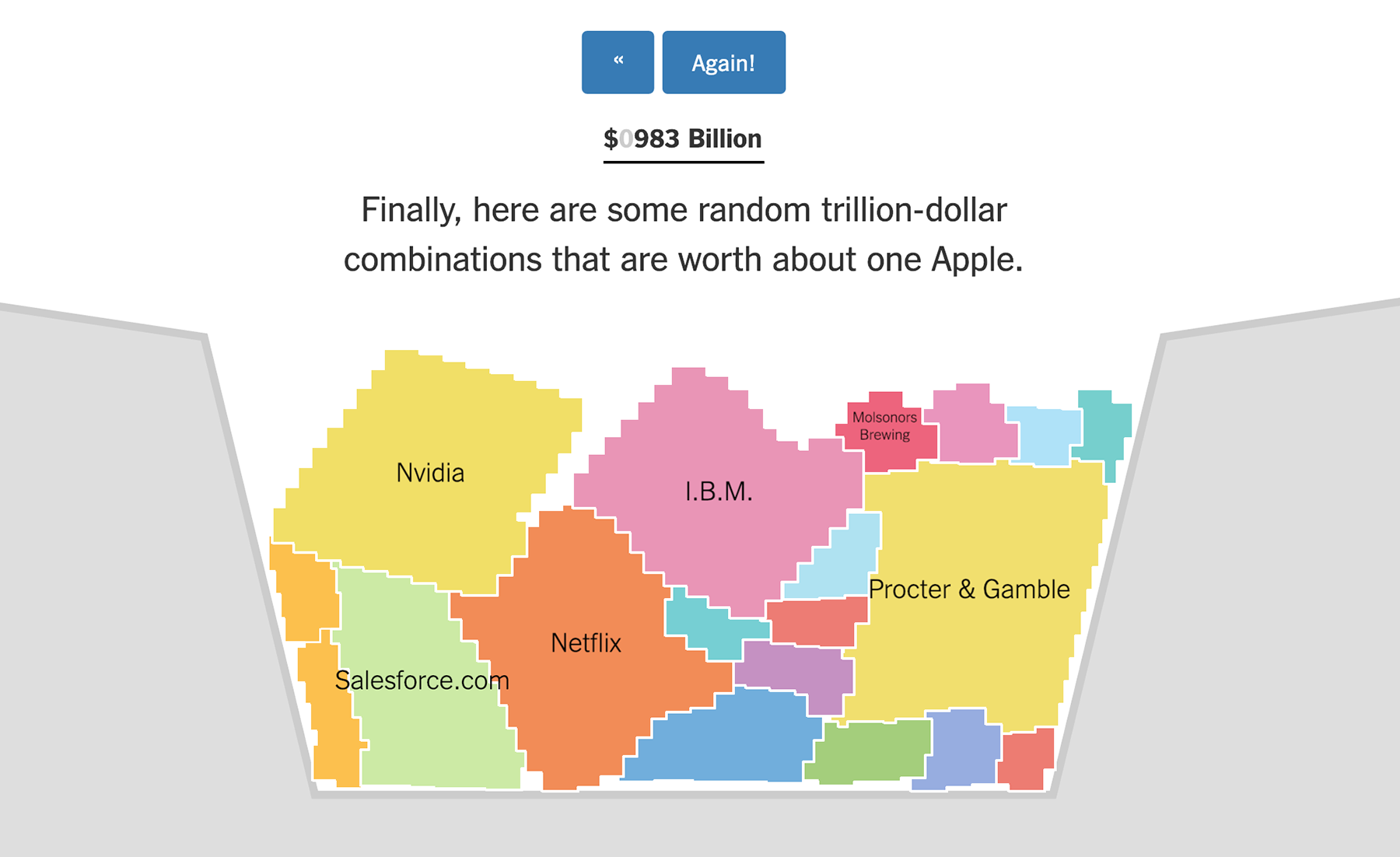
Маленькая, да удаленькая визуализация, посвящённая «триллионному» рубежу компании Эппл:
У визуализации очень приятная механика, которую не передать статичными картинками — нечто среднее между тетрисом и «карандашной физикой» (Сrayon Physics). А ещё она очень понравилась Яне. Сидя у меня на коленях, пока я в ночи составляла этот список, она без конца просила: «Включи ту зацию, где вываливаются разноцветные штуки». И я включала, снова и снова :-)
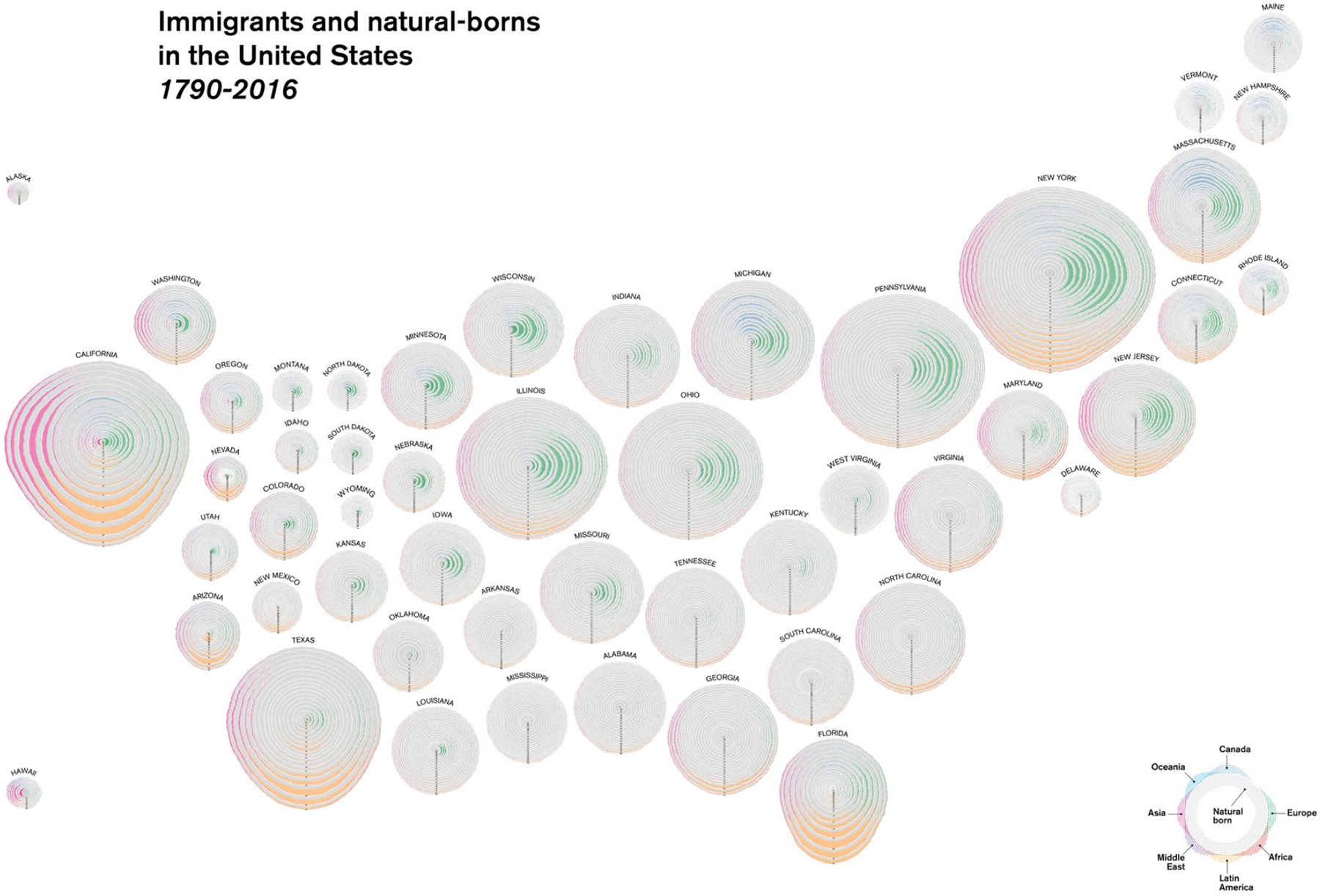
Безумно красивая идея от «Нэшнл-географик» — волны иммиграции показаны как годовые кольца дерева:
Цветные пики по секторам — приток приезжих из той или иной части света. В «увеличительном стекле» показано, что график состоит из атомов — чёрточек, каждая чёрточка — 100 «одноцветных» иммигрантов. Благодаря такой дробности, формат работает и в разбивке по штатам:
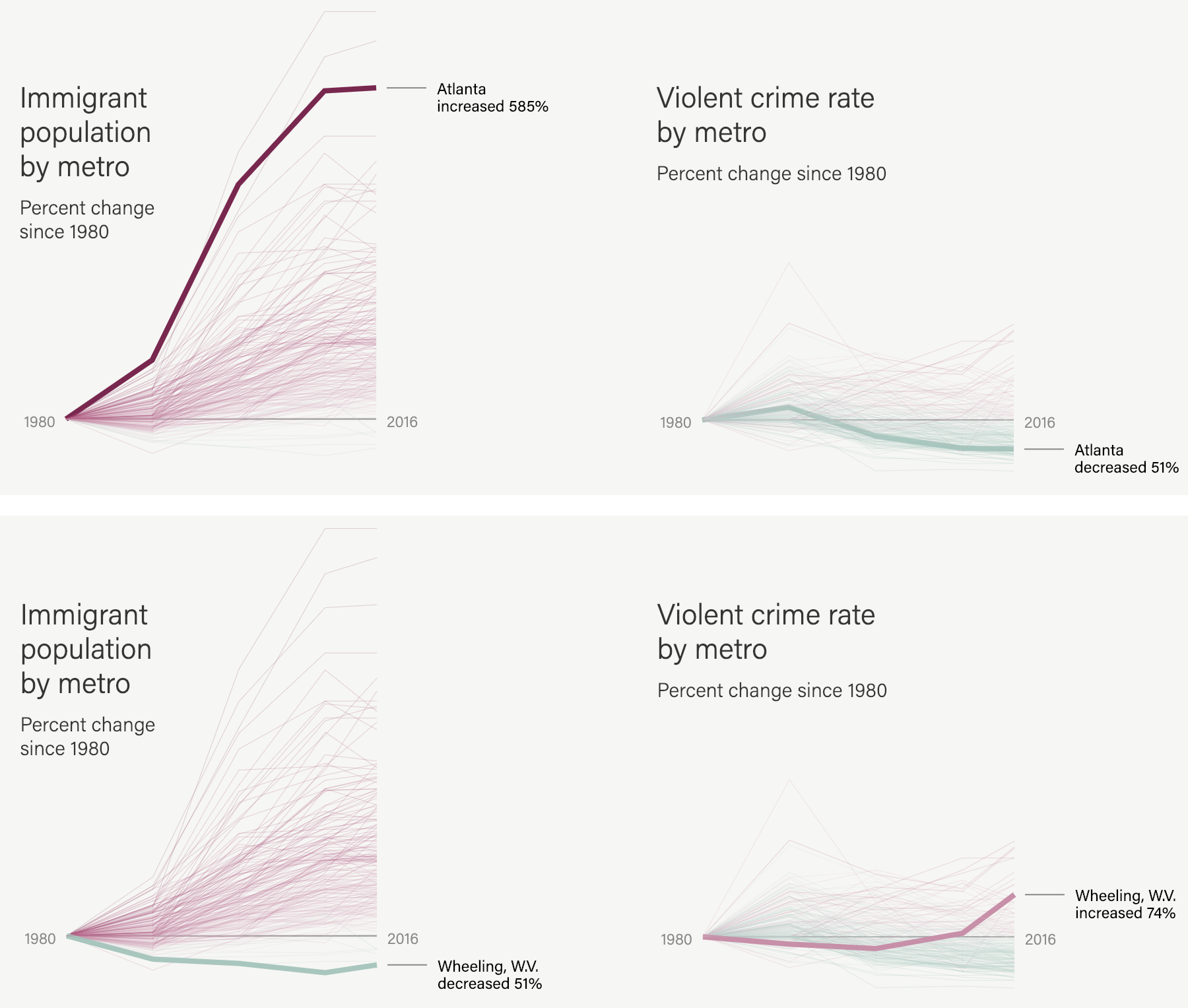
Ещё одна визуализация на тему иммиграции опровергает связь между притоком иммигрантов и ростом преступности:
Обратите внимание, как множество графиков работают вместе, не превращаясь в кашу.
Города
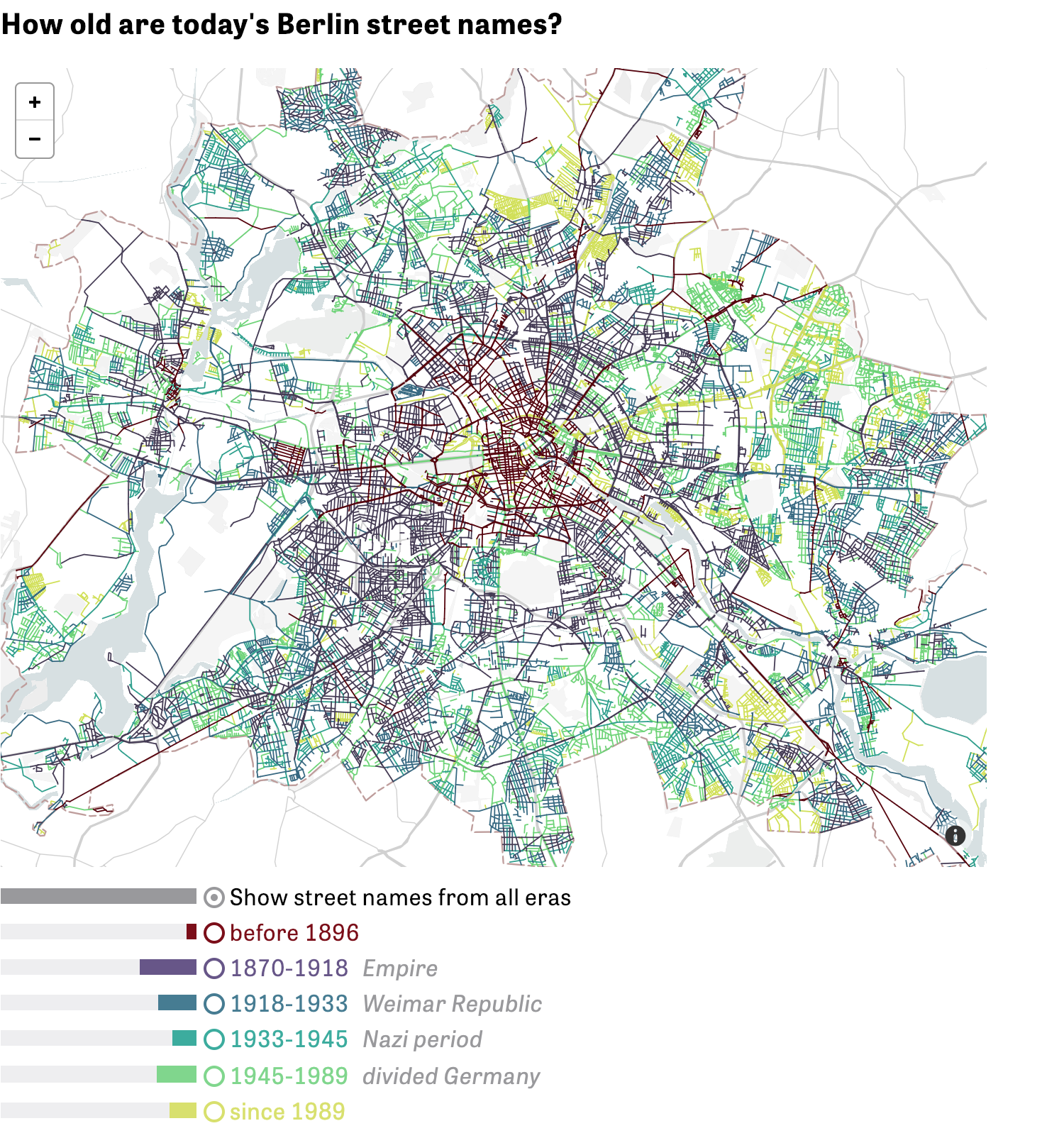
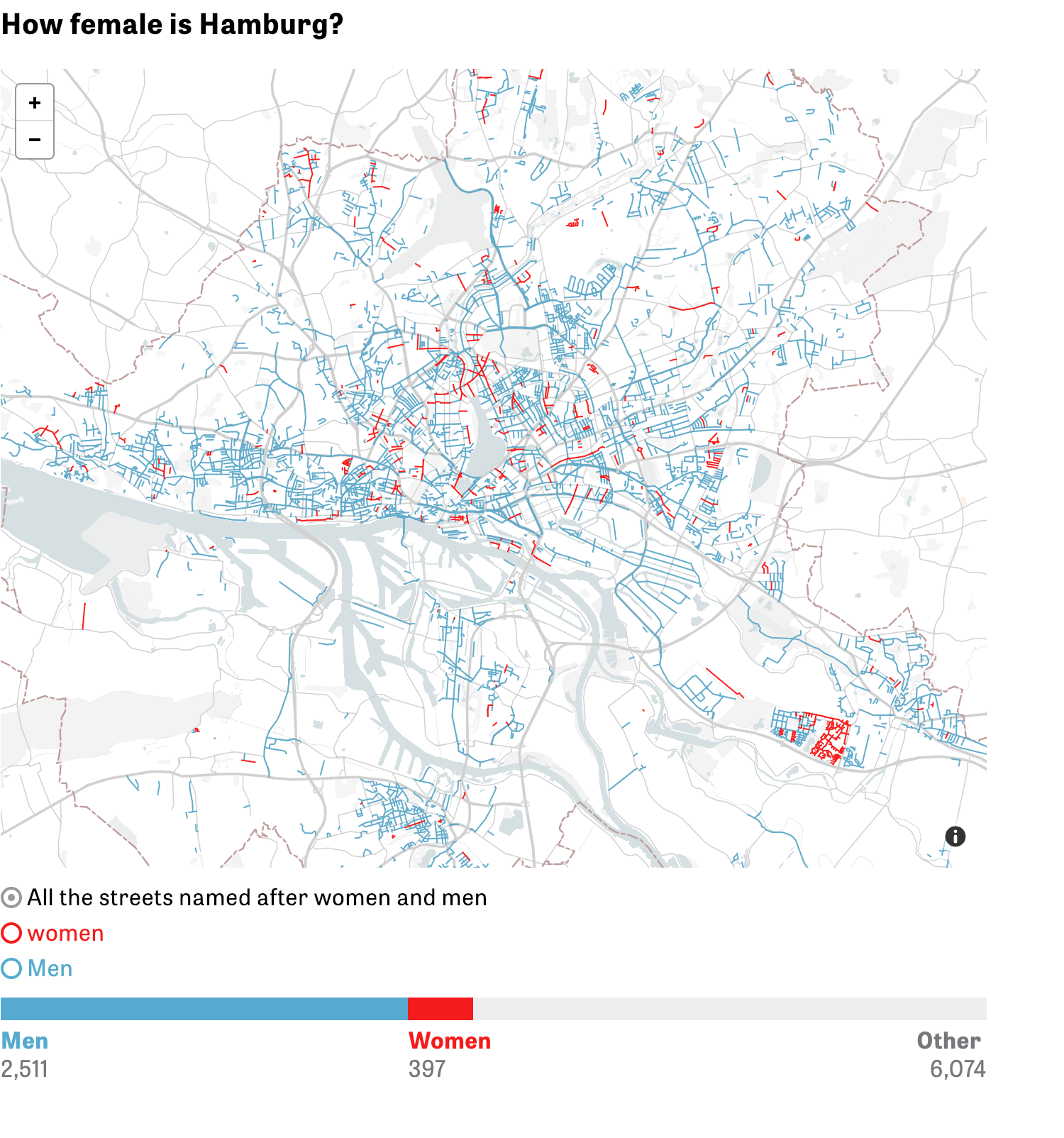
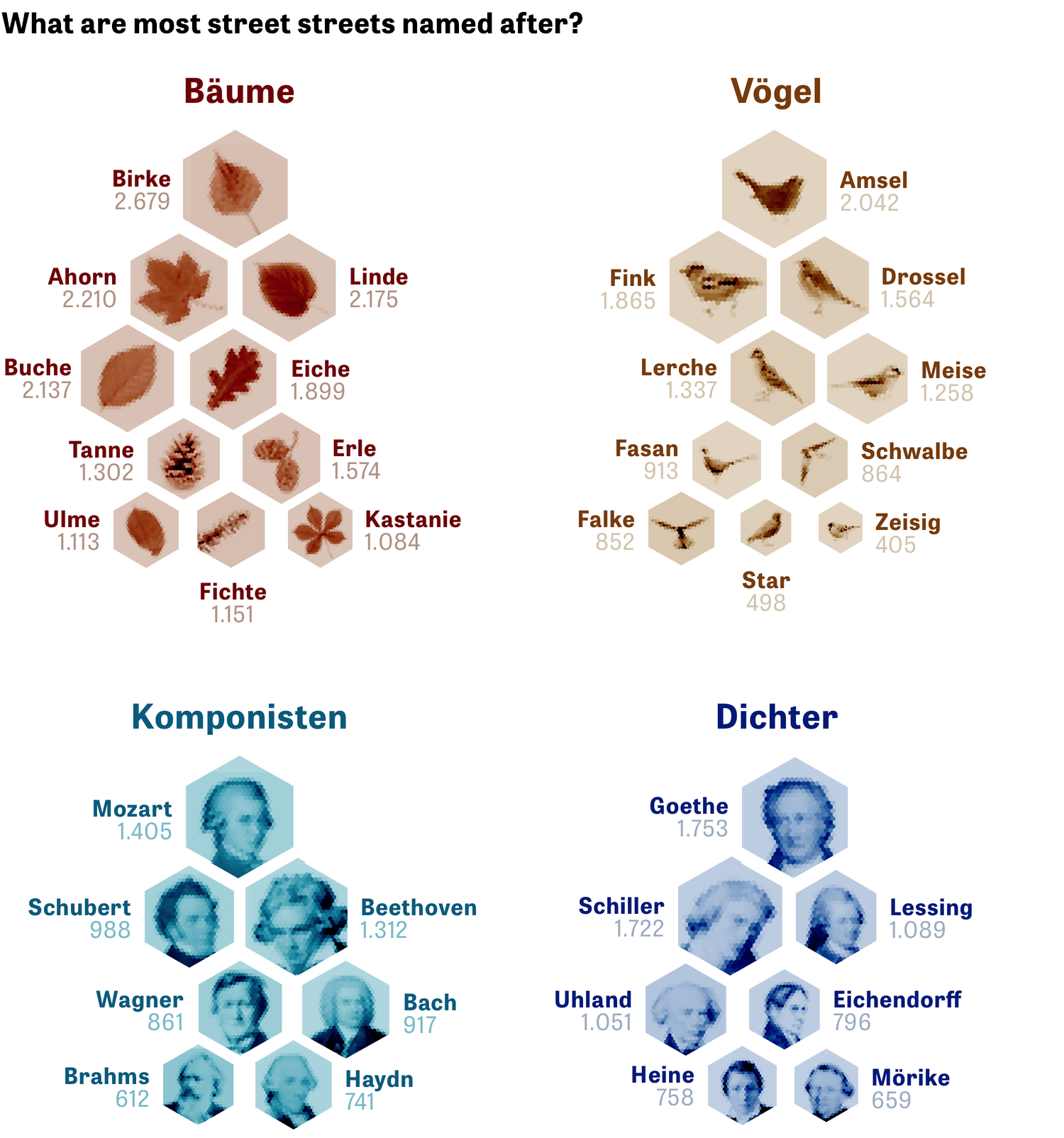
Глубокое и необычное исследование названий улиц в немецких городах:
Я читала немецкую статью, переведённую браузером на английский. В английскую версию статьи на сайте большая часть «вкуснятины» не вошла.
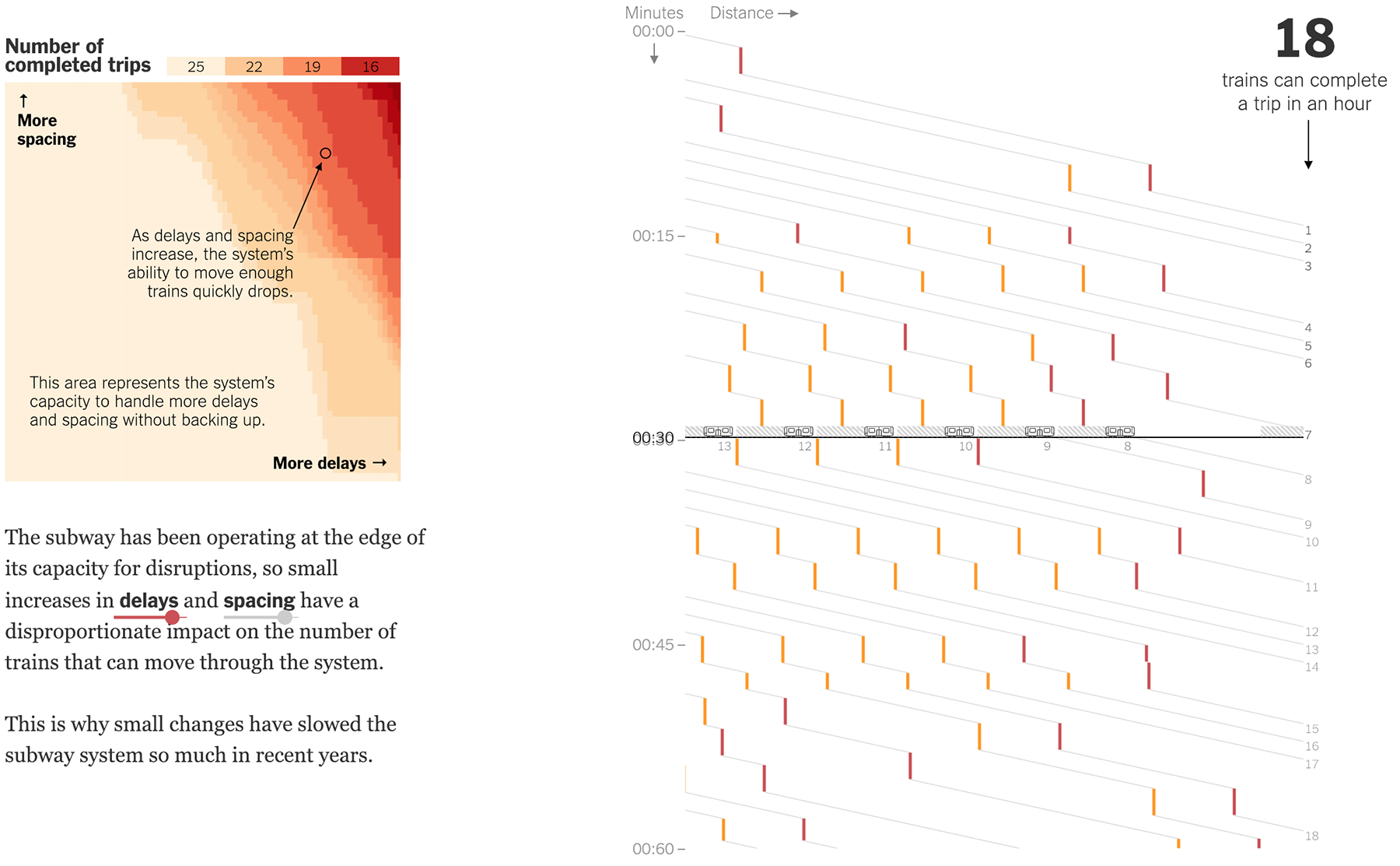
Исследование причин задержек в Нью-йоркском метро с анимированными пояснениями и подробной интерактивной моделью наглядно демонстрирует причины транспортного кризиса:
На этой шестой по счёту визуализации от Нью-йорк-таймс скорее всего сработает ограничение на просмотр. Если не планируете оформлять подписку, воспользуйтесь режимом «Инкогнито».
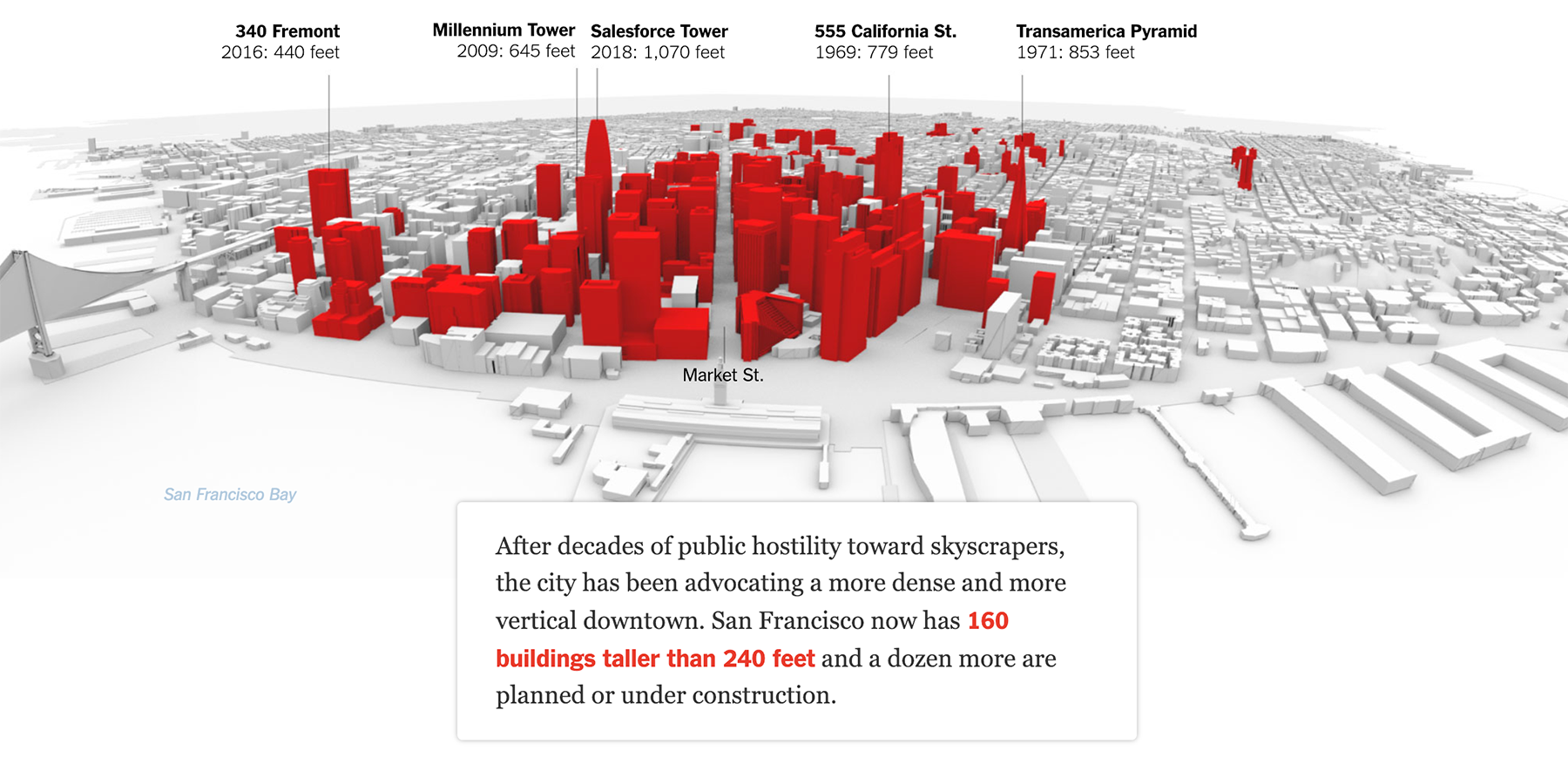
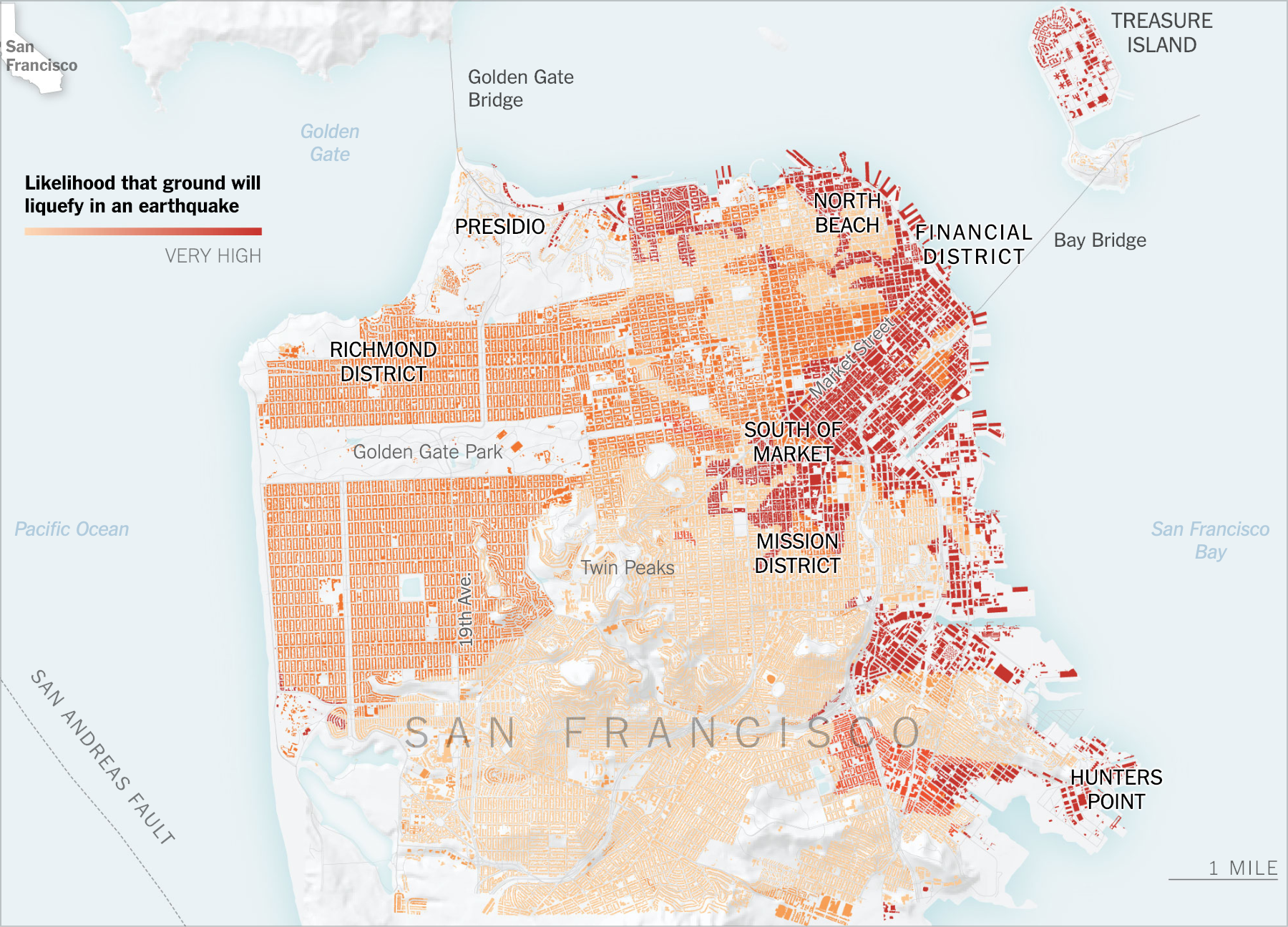
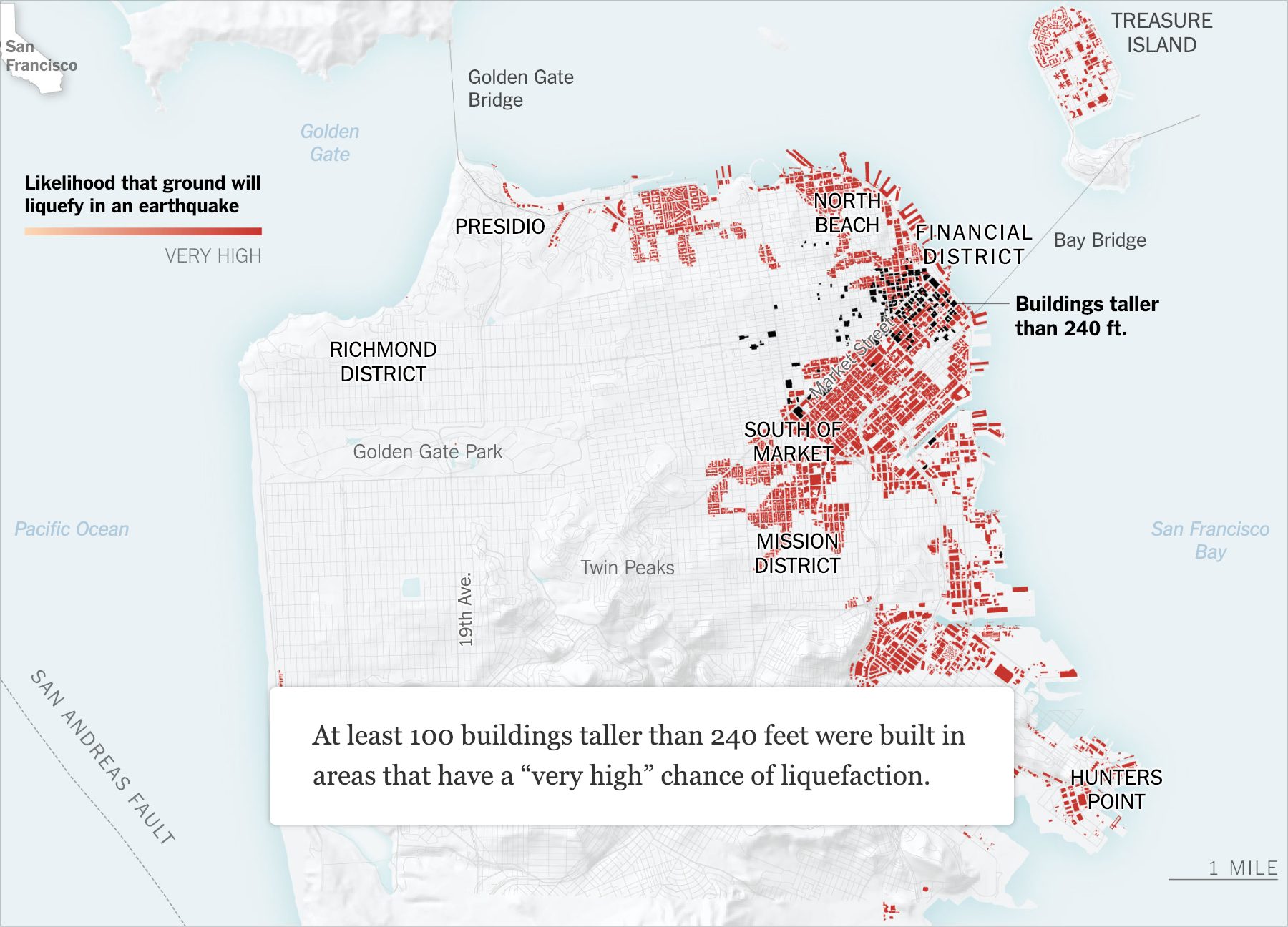
Ещё одна эффектная городская визуализация — сейсмоопасные небоскрёбы Сан-Франциско:
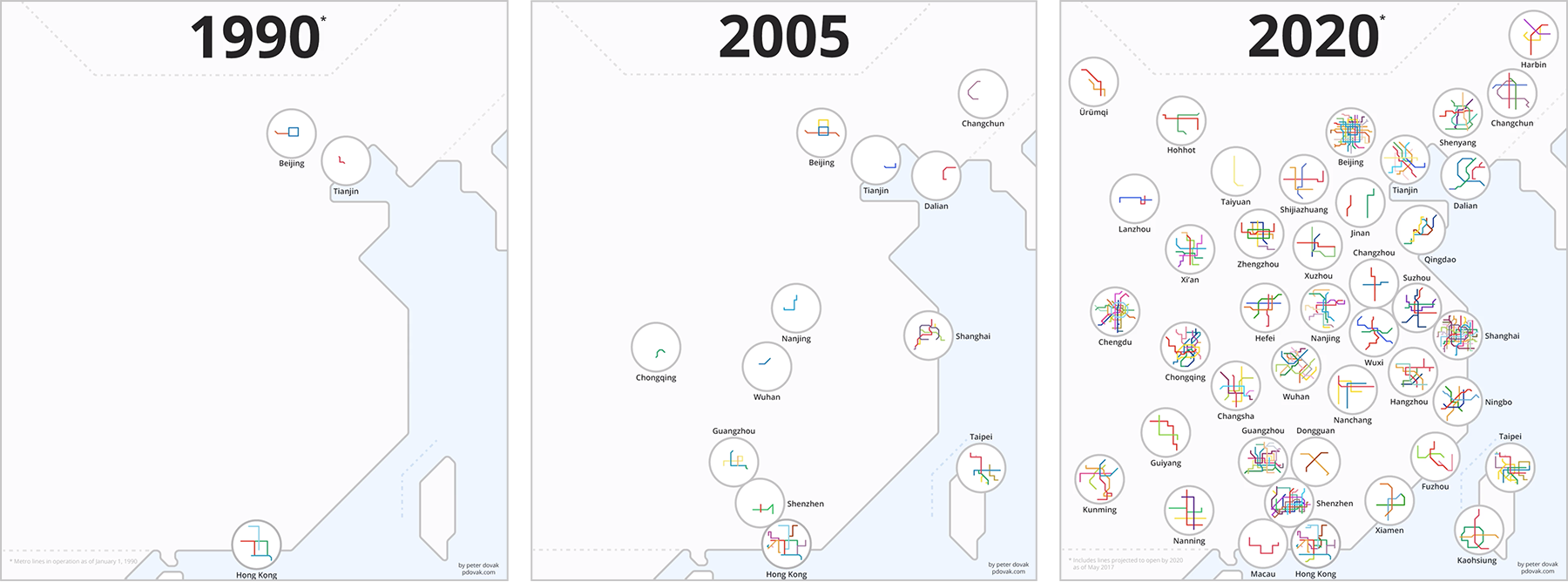
Эволюцию метро в городах Китая с 1990 по 2020 годы в формате гиф:
Природа и экология
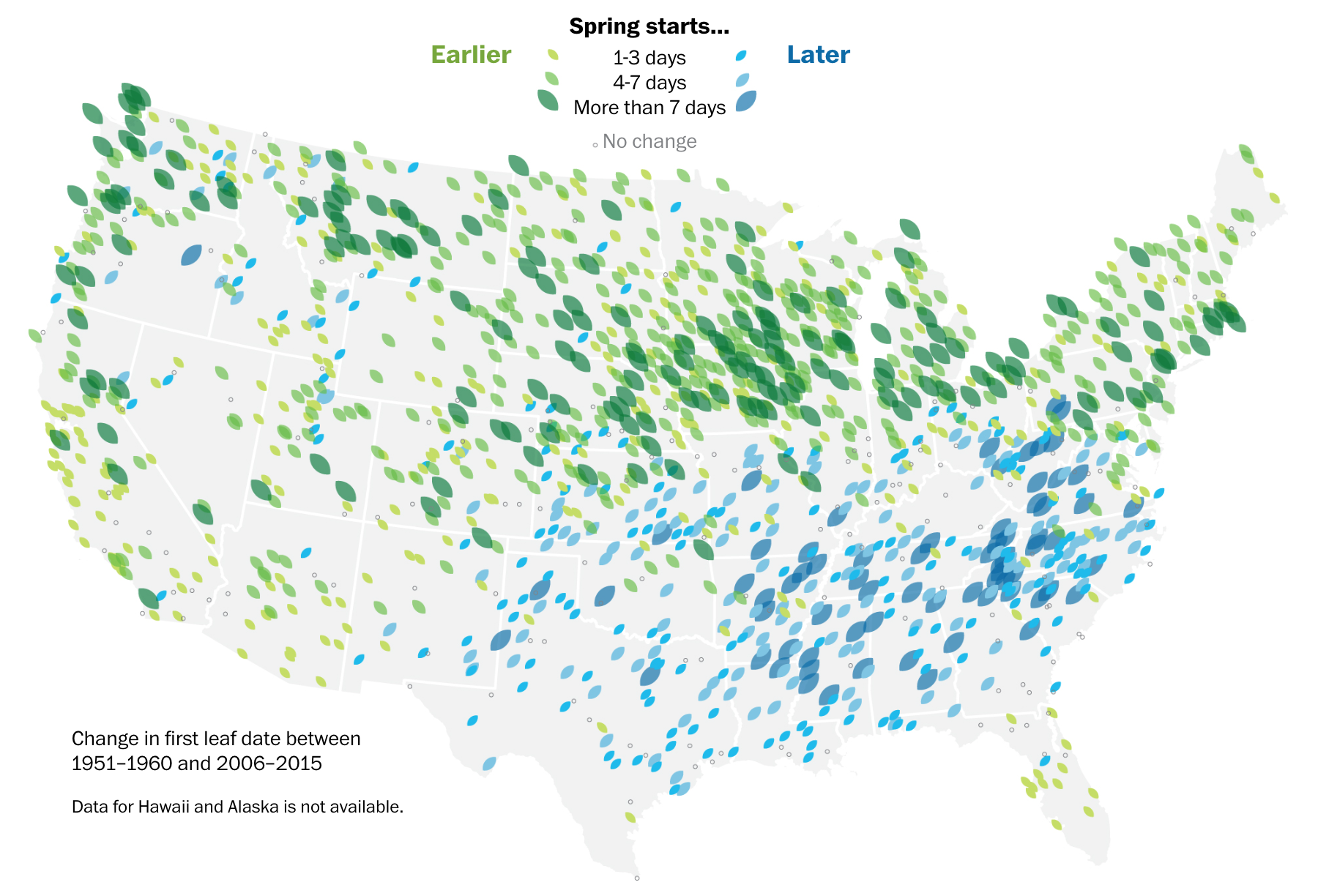
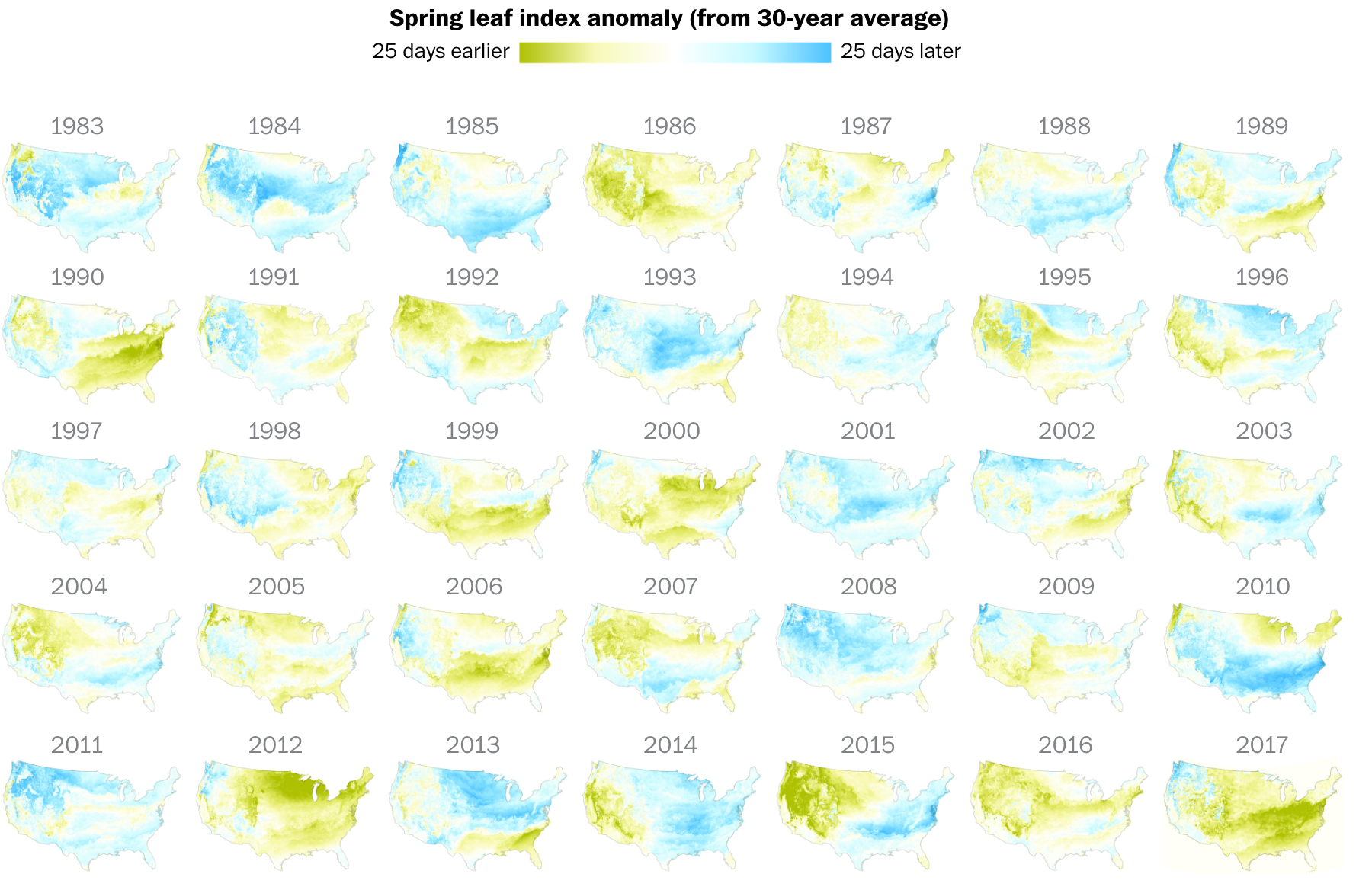
Изящная карта с первыми листочками показывает раньше или позже приходит весна в разные регионы США по сравнению с данными 50-летней давности:
Замечательный пример буквального кодирования — по всей карте «распускаются» первые листочки. Здесь же картина по годам за последние 35 лет. Видно, что хотя «в среднем по больнице» весна приходит раньше, года между собой отличаются довольно значительно, как в одну, так и в другую сторону:
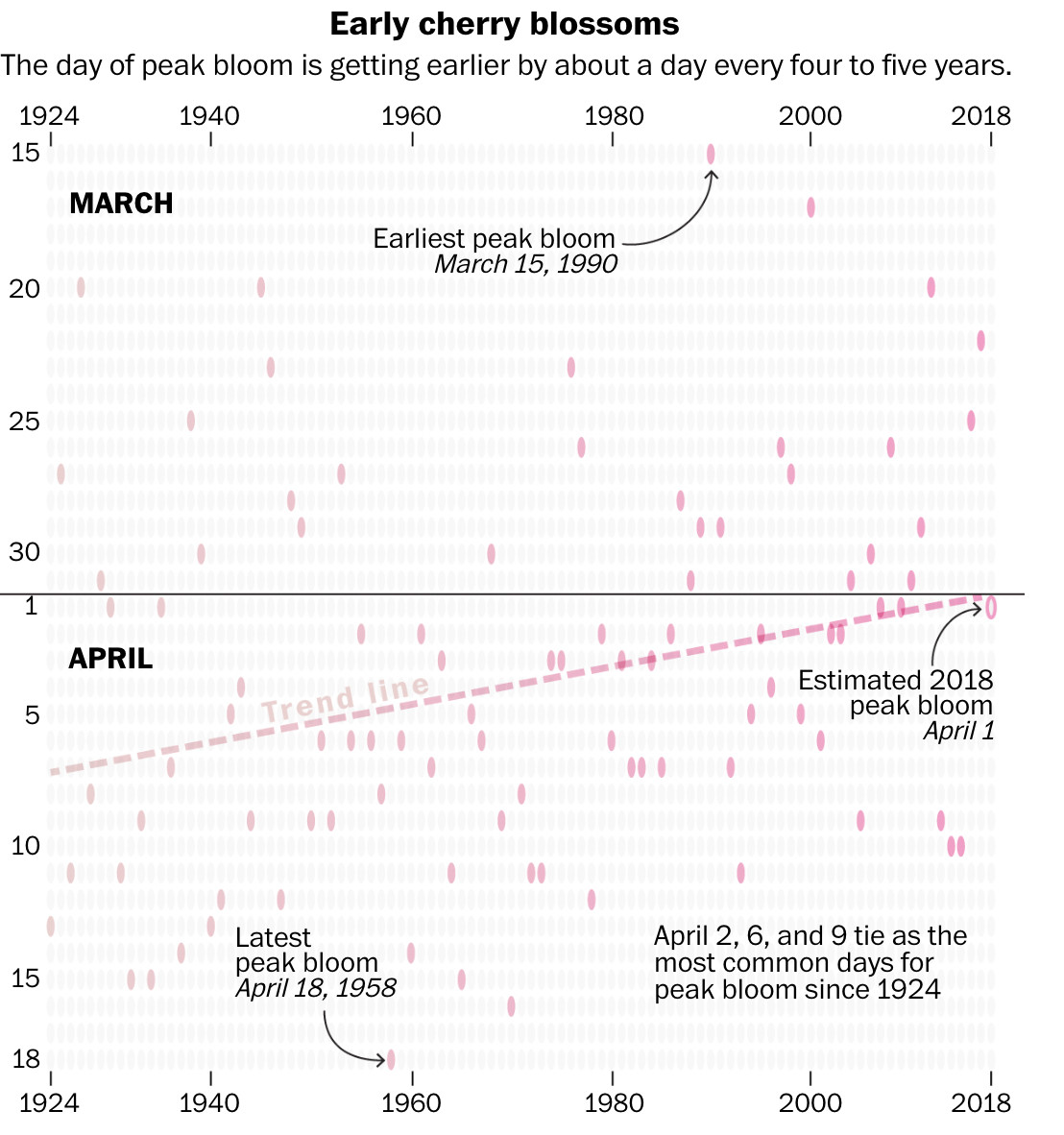
В той же статье есть и график цветения вишни с точками-лепестками. Интересно, насколько точным оказался прогноз на 2018-й?
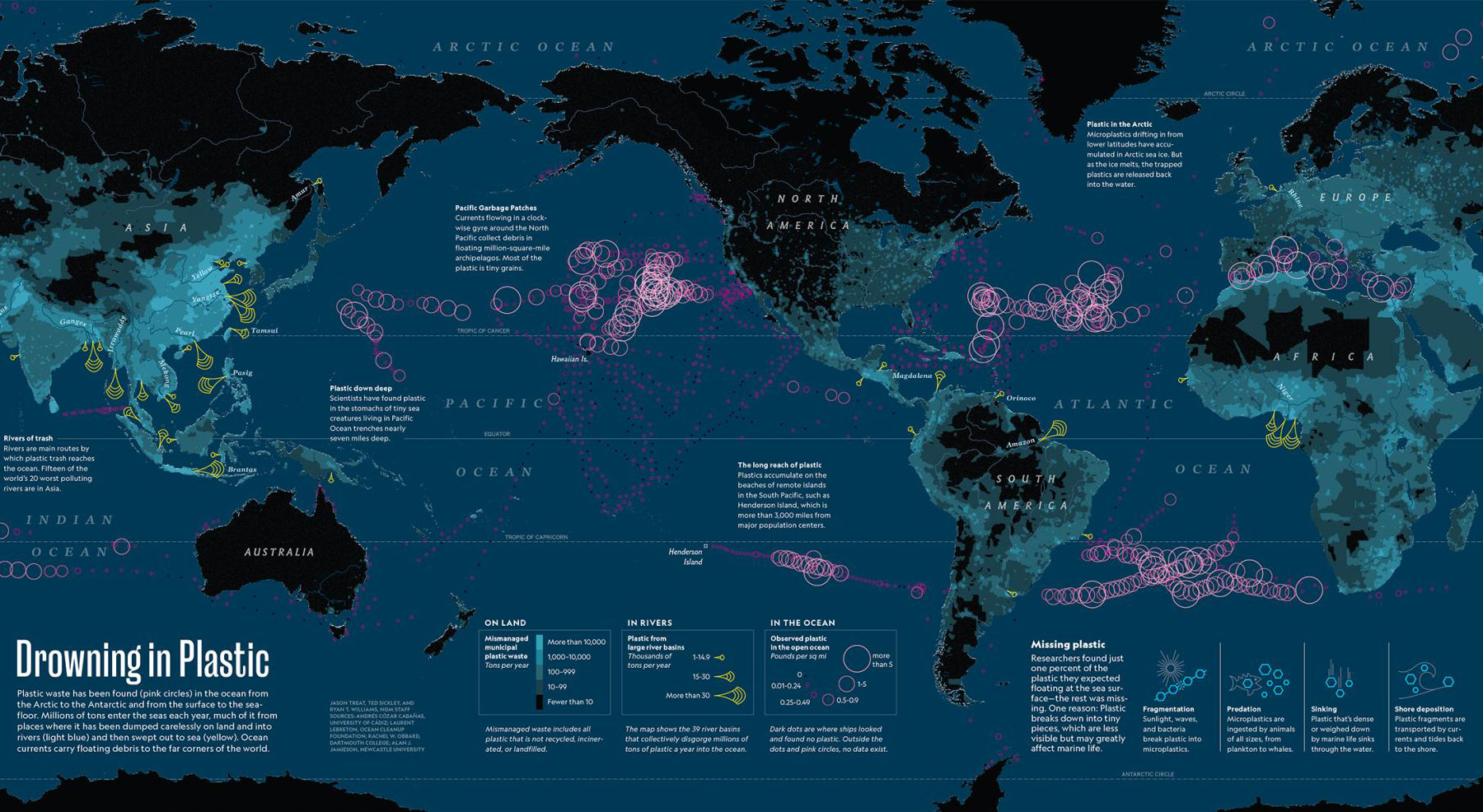
Плакат и интерактивная визуализация о загрязнении морей пластиком:
На карте показано три среза данных: страны закрашены тем ярче, чем больше пластиковых отходов производят, светло-жёлтые воронки в устьях рек показывают, сколько пластика приносит река в открытое море, а круги в океане — это плавучие скопления пластикового мусора. Обратите внимание, что отсутствие кругов не означает отсутствие мусора. Области, где исследовательские суда не обнаружили пластика показаны чёрными точками, и их не так уж много по сравнению с подтверждёнными «мусорными кучами».
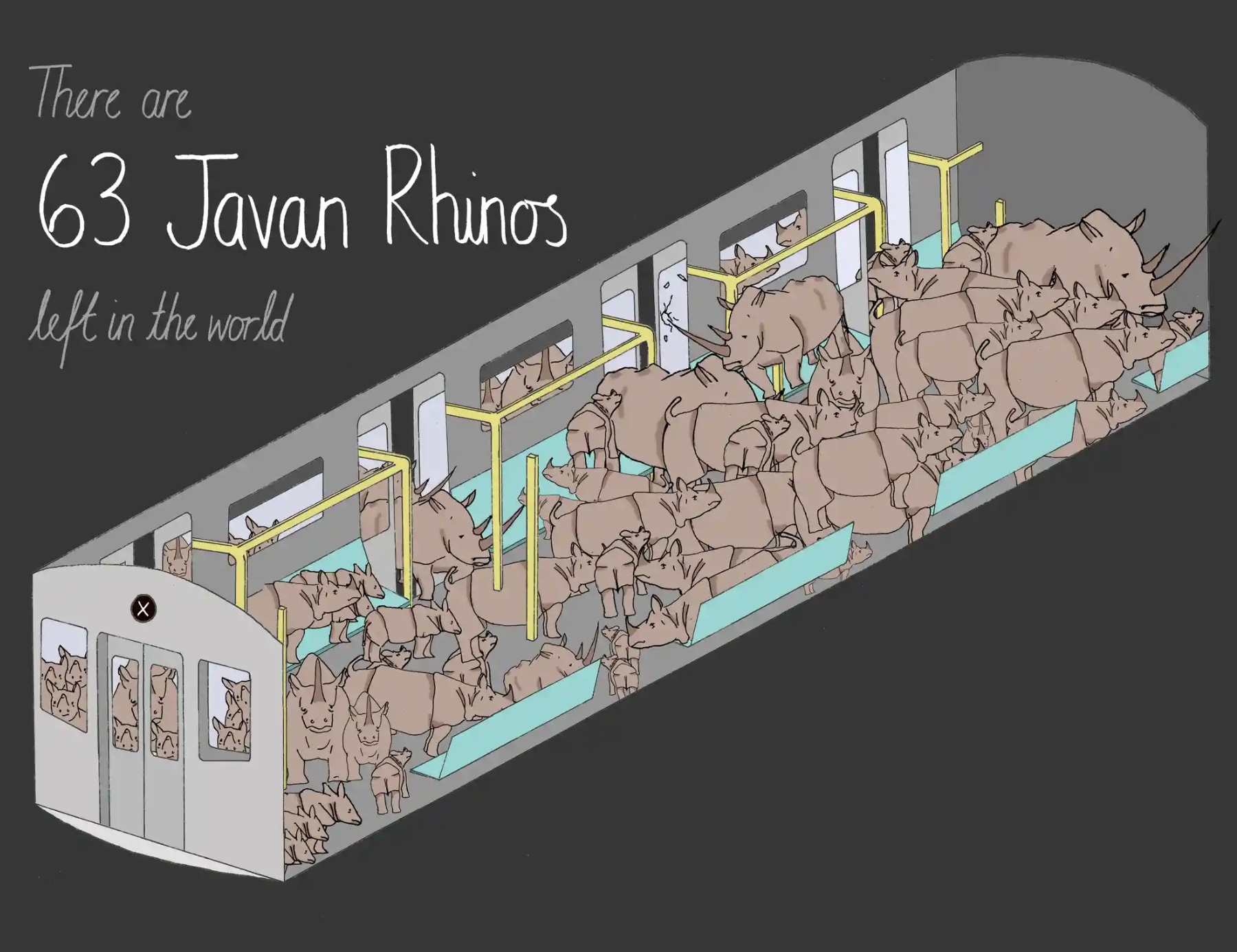
Трогательные изображения семи исчезающих видов, которых осталось так мало, что все их представители помещаются в вагон метро:
Там, где сухое число скорее всего оставило бы читателя равнодушным, автор нашла понятную, наглядную и близкую большинству метафору и воплотила её в выразительной графической форме.
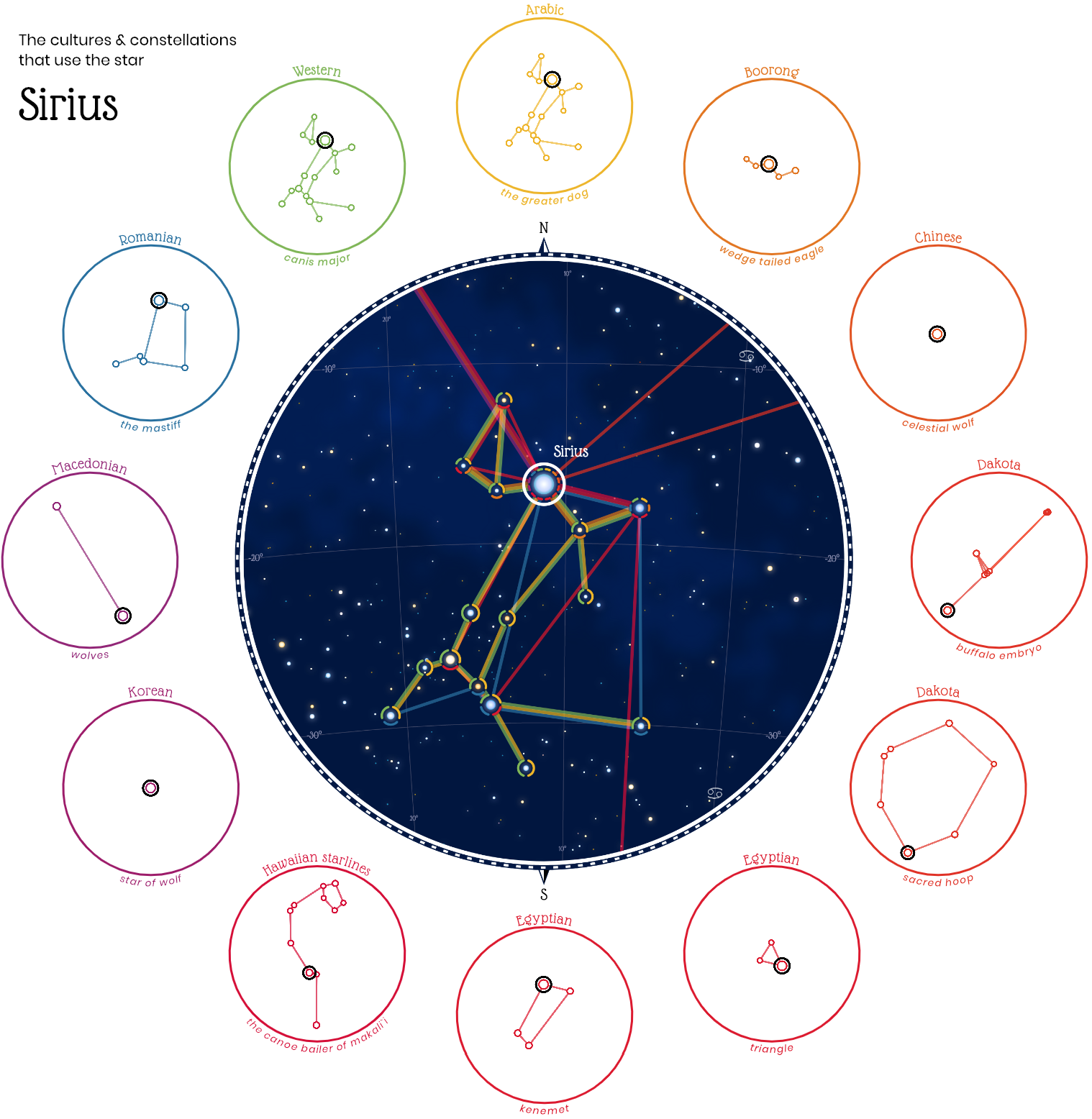
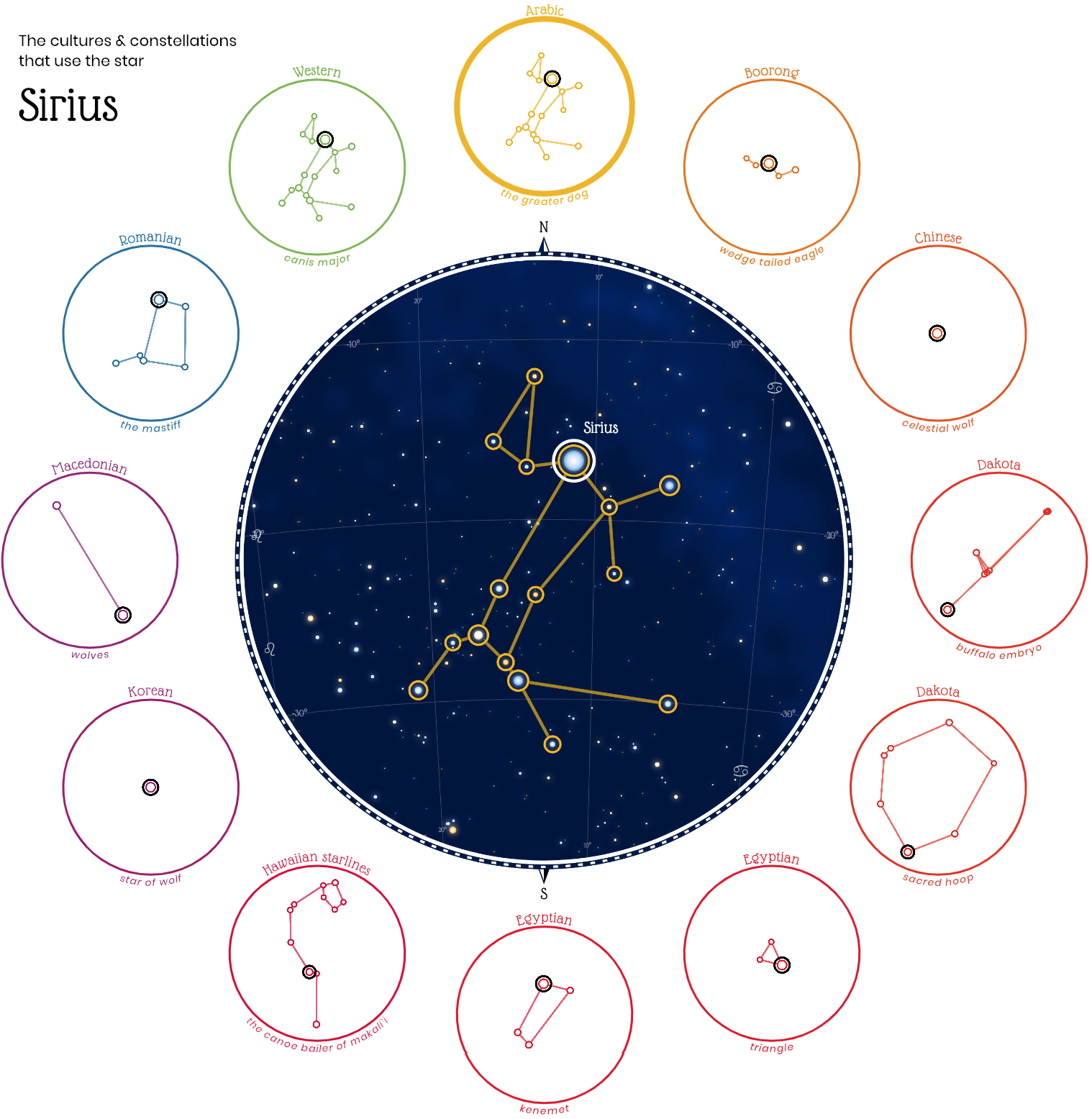
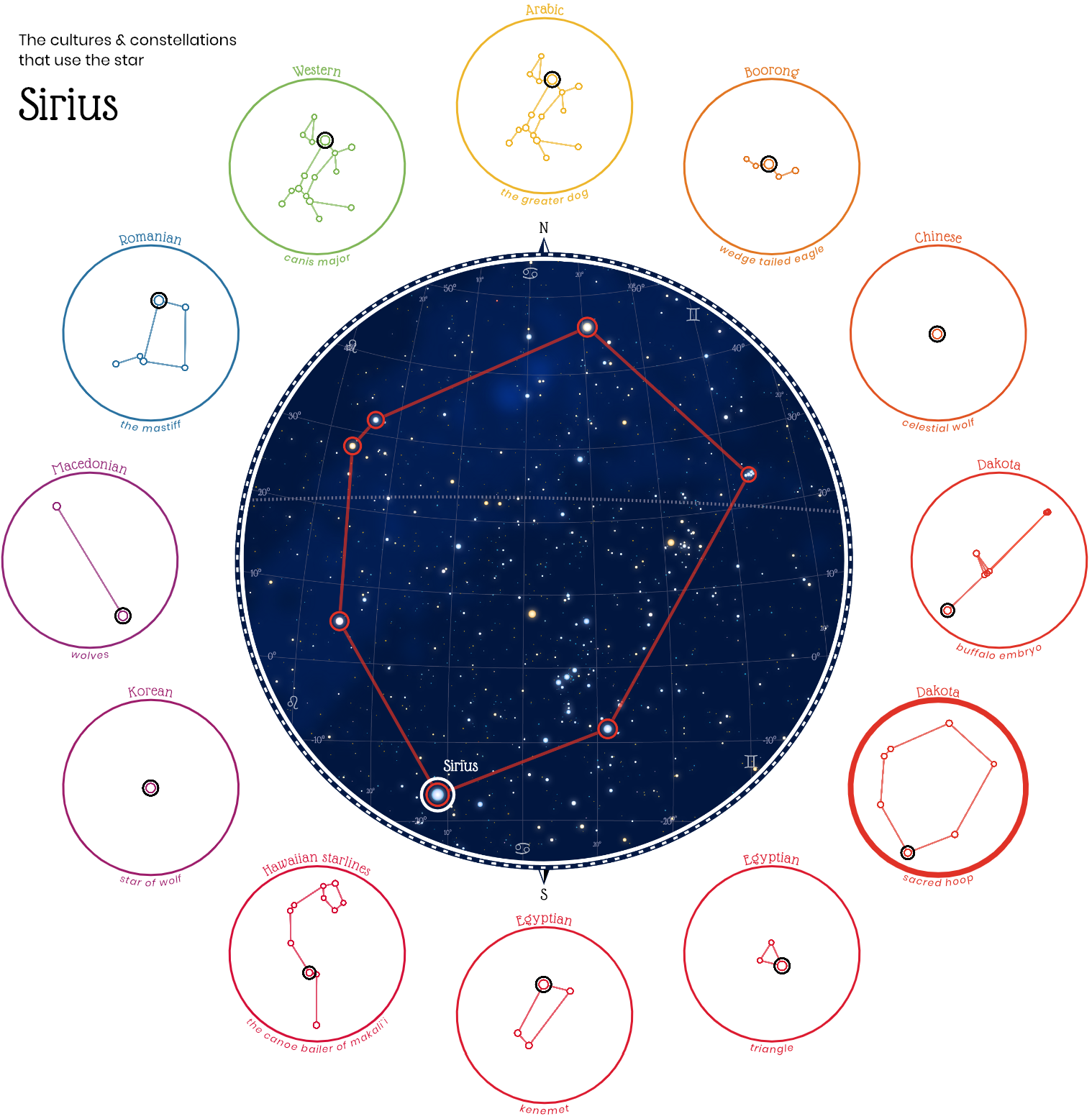
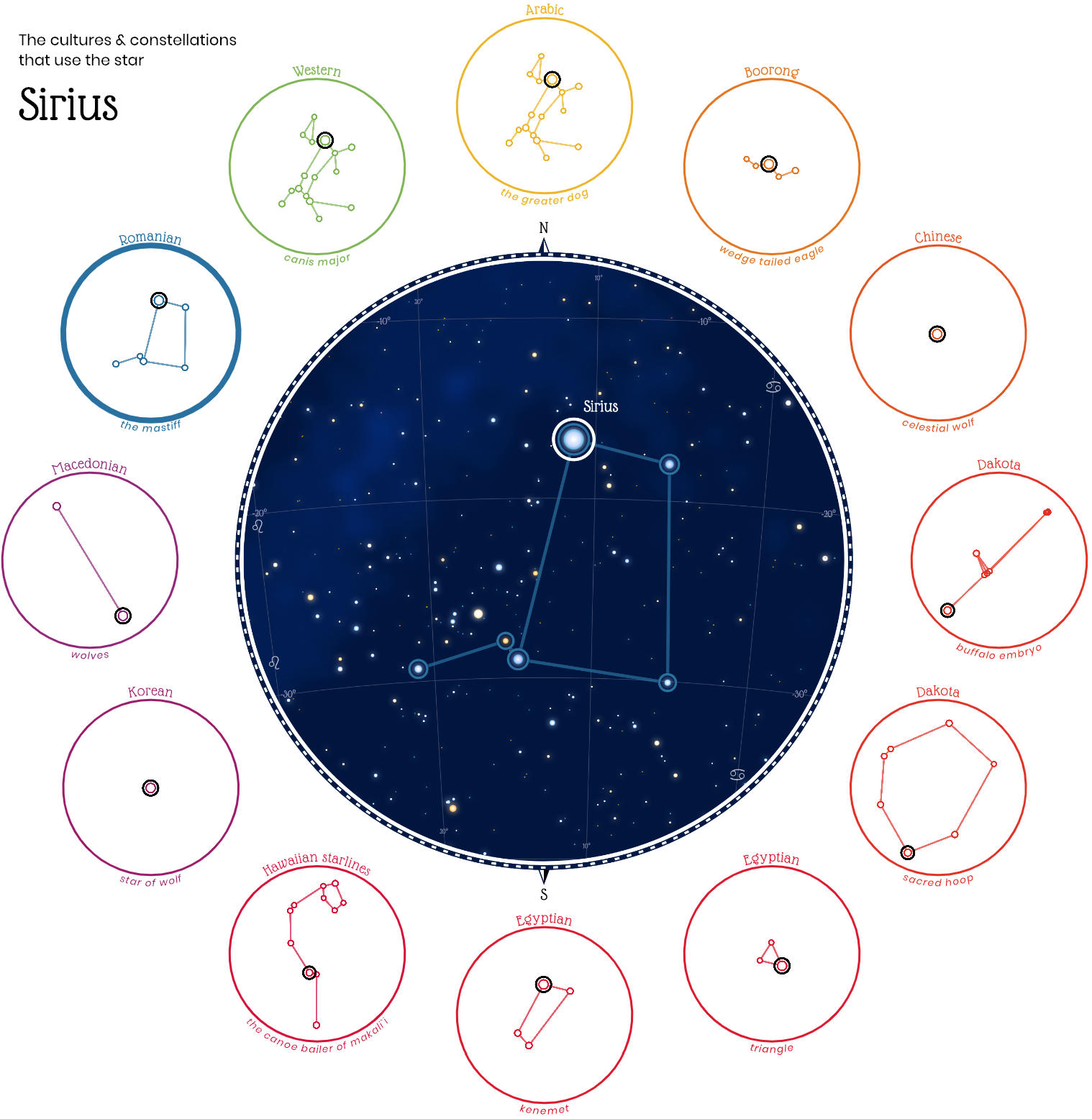
Любопытный проект «Небесные фигуры», который собрал воедино 28 систем созвездий разных мировых культур:
Все жители Земли во все времена смотрели на одно и то же звёздное небо. Во многих культурах звёзды объединяли в небесные фигуры. На визуализации можно взглянуть на небо глазами арабов, китайцев, египтян, индусов, ацтеков и других народов, а также увидеть созвездия, связанные в разных культурах с одними и теми же звёздами.
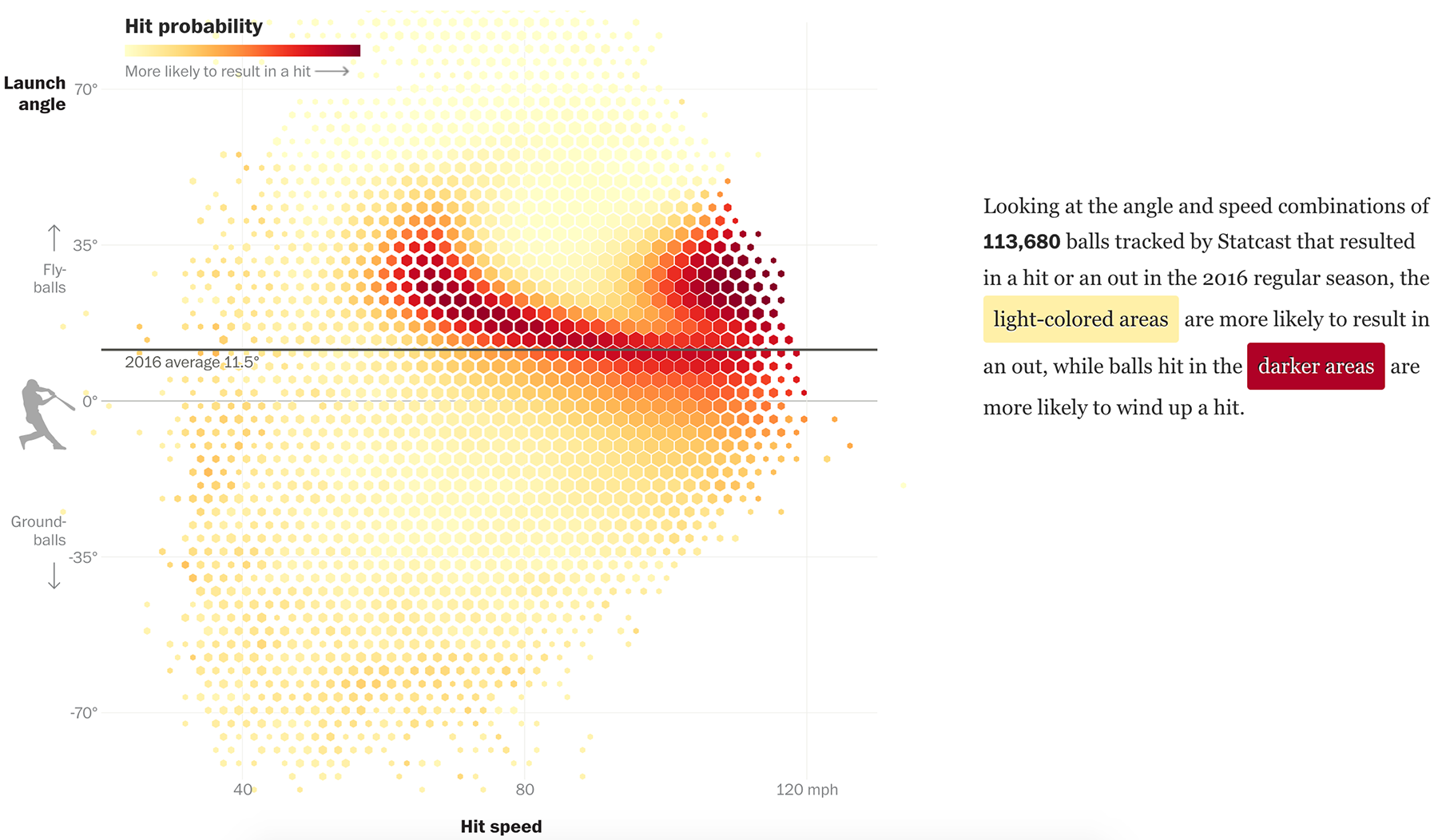
Cпорт
Зимняя олимпиада как обычно богата на графику, но примечательных визуализаций мне удалось найти не так уж много.
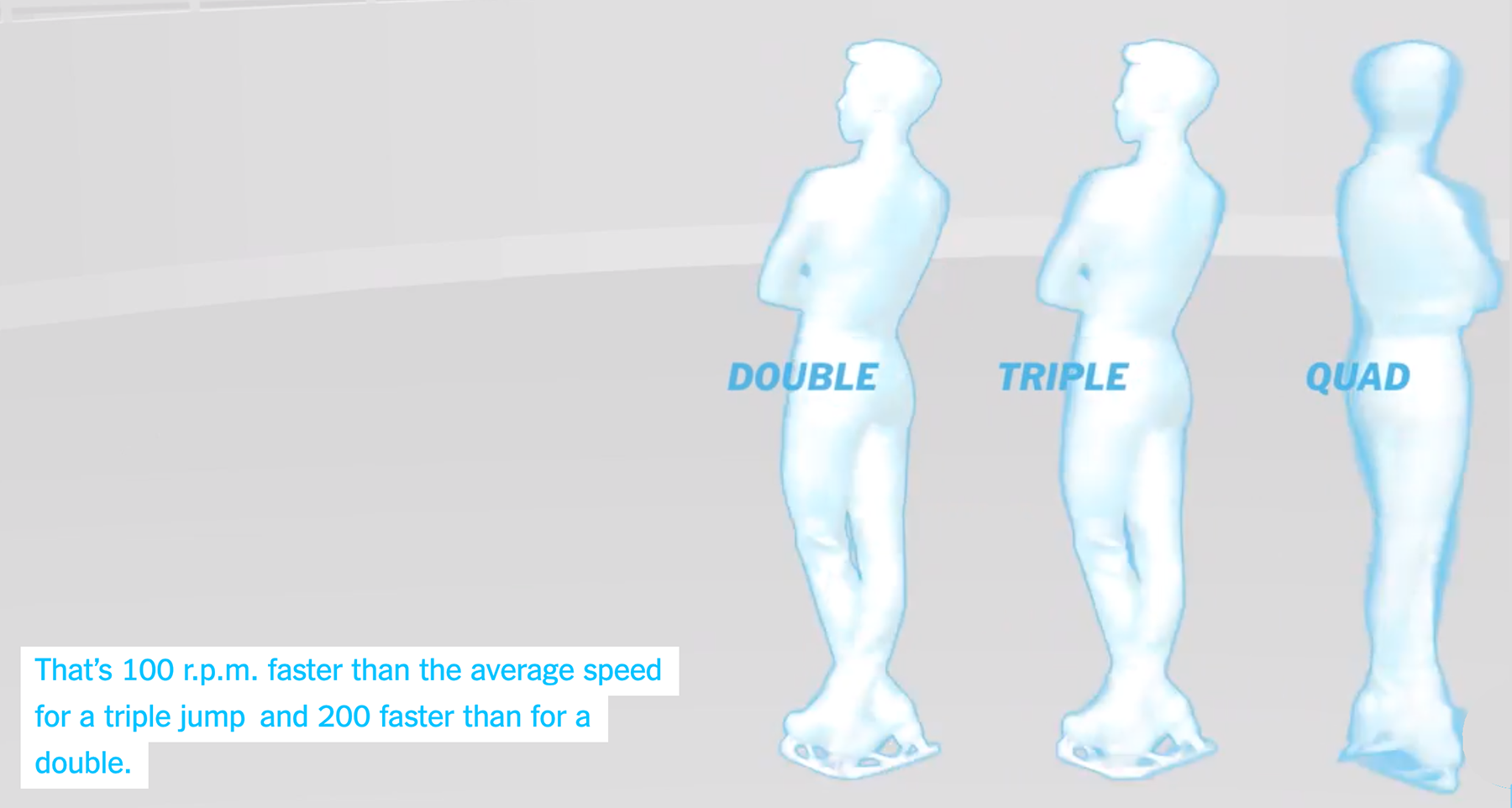
Самым интересным мне показался сюжет с графическим объяснением сложных трюков фигуристов, лыжников и сноубордистов:
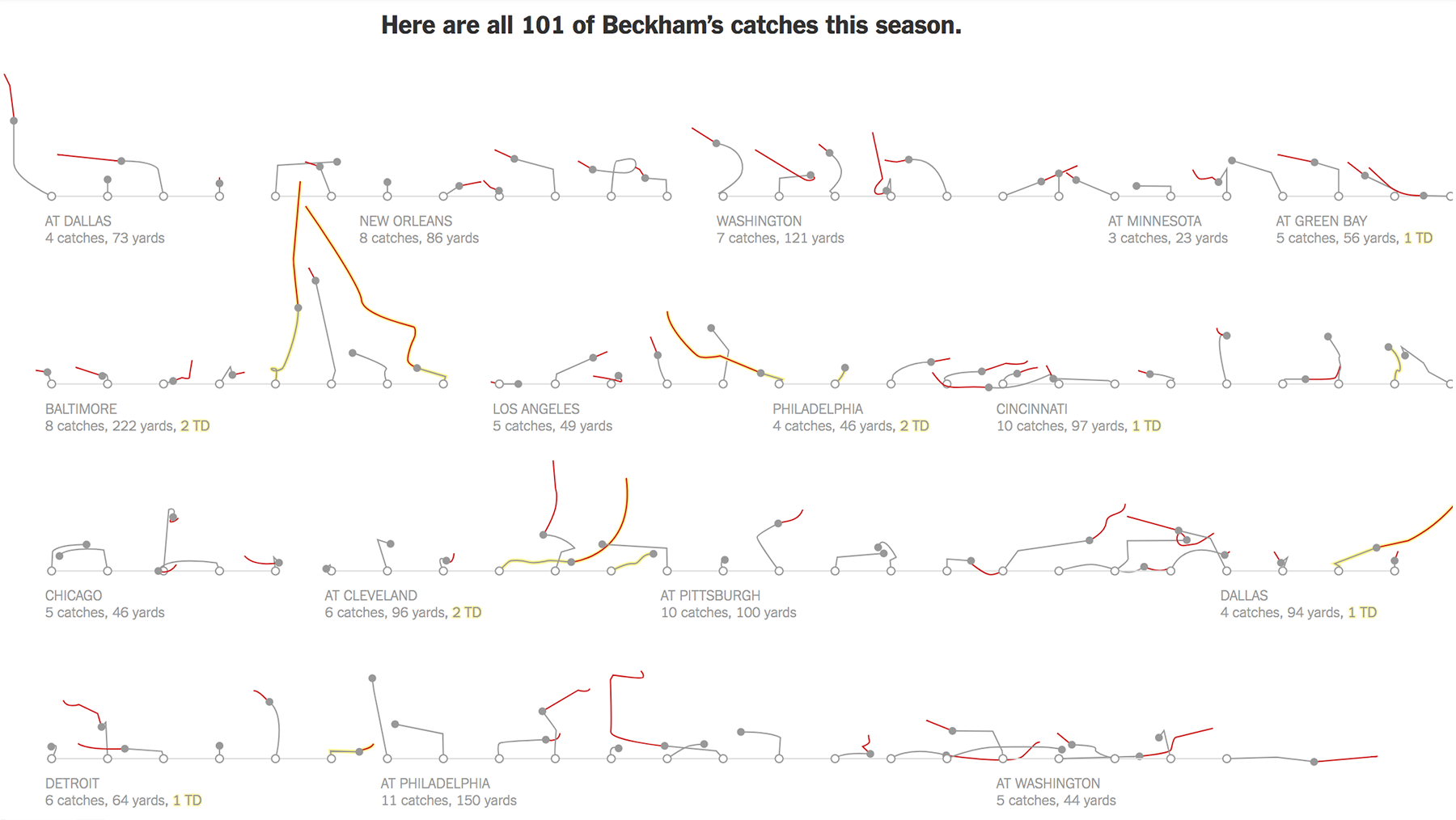
Уже привычный, но от этого не менее захватывающий спортивный формат — раскадровка:
На прошлой олимпиаде Нью-йорк-таймс использовали гениальные живые превьюшки соревнований. В этом году изображения стали более детализированными, сохранив при этом лаконичность исходного формата:
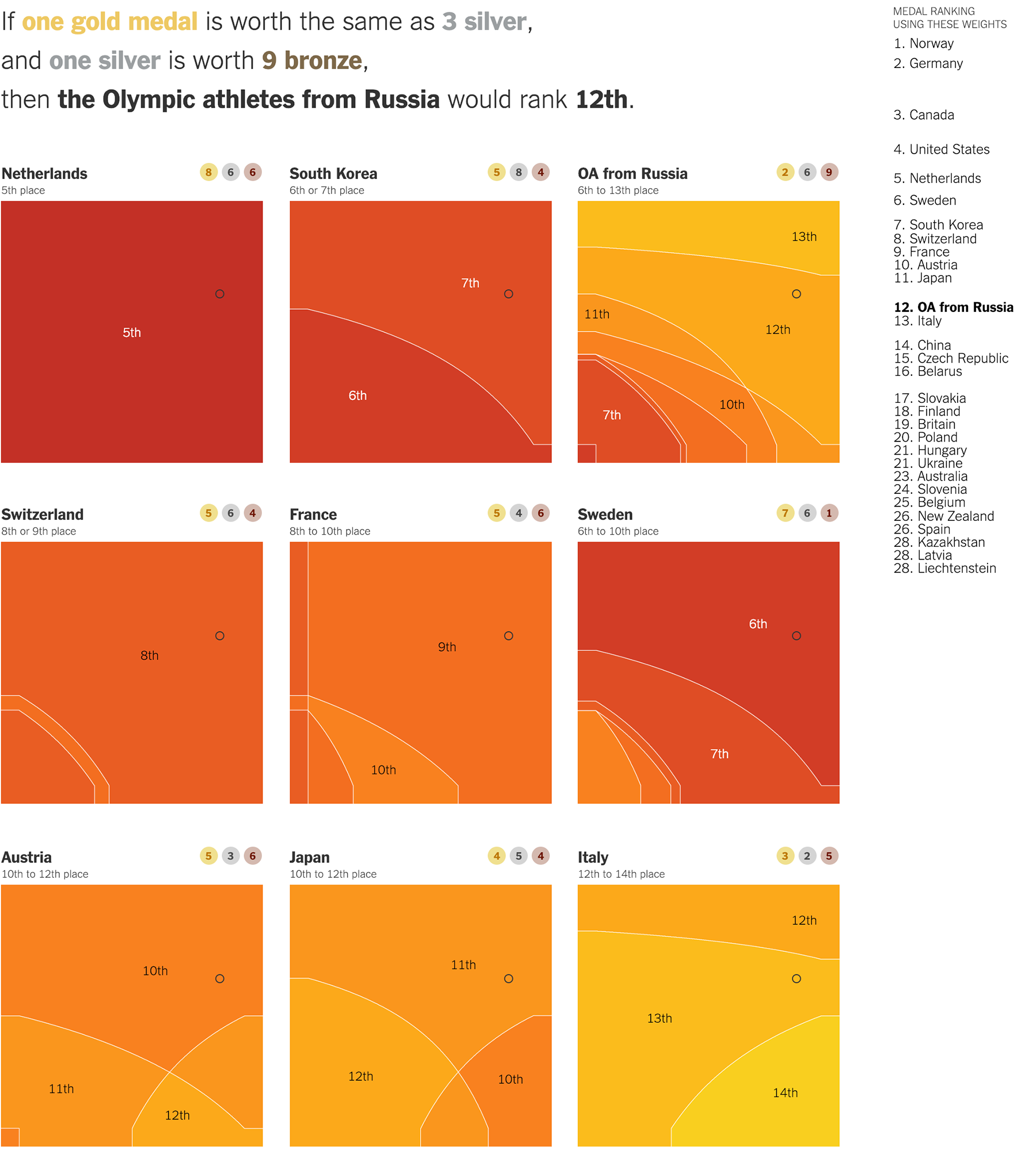
Визуализация, которая раз и навсегда закрыла вопрос о первенстве по медалям, рассчитывает место в общем списке по всевозможным системам от «все медали одинаковы» до «только золото имеет значение»:
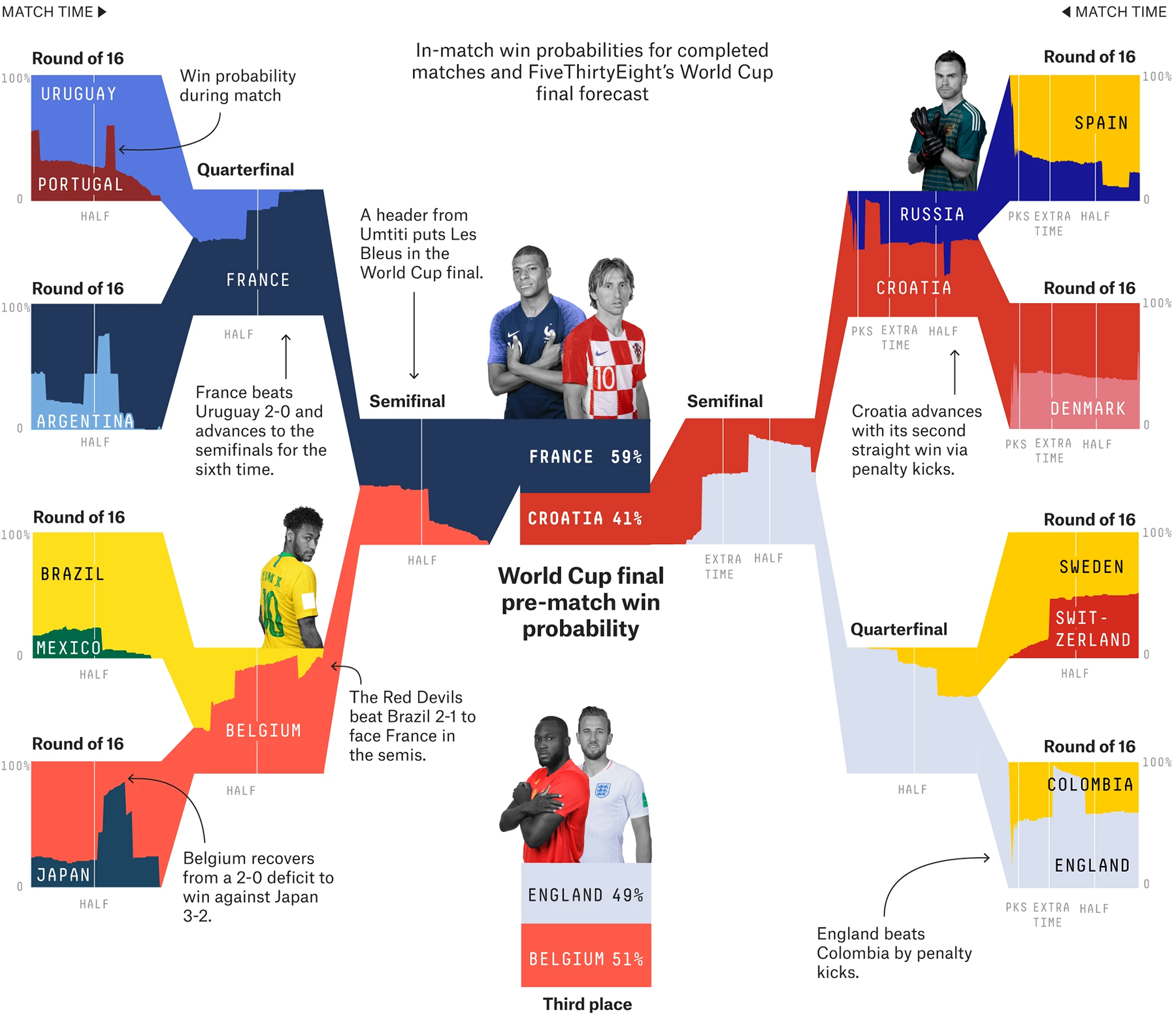
Весь чемпионат мира по футболу, начиная с одной восьмой финала:
Очень здорово показано, как в ходе игры менялись шансы на победу команды.
Искусство
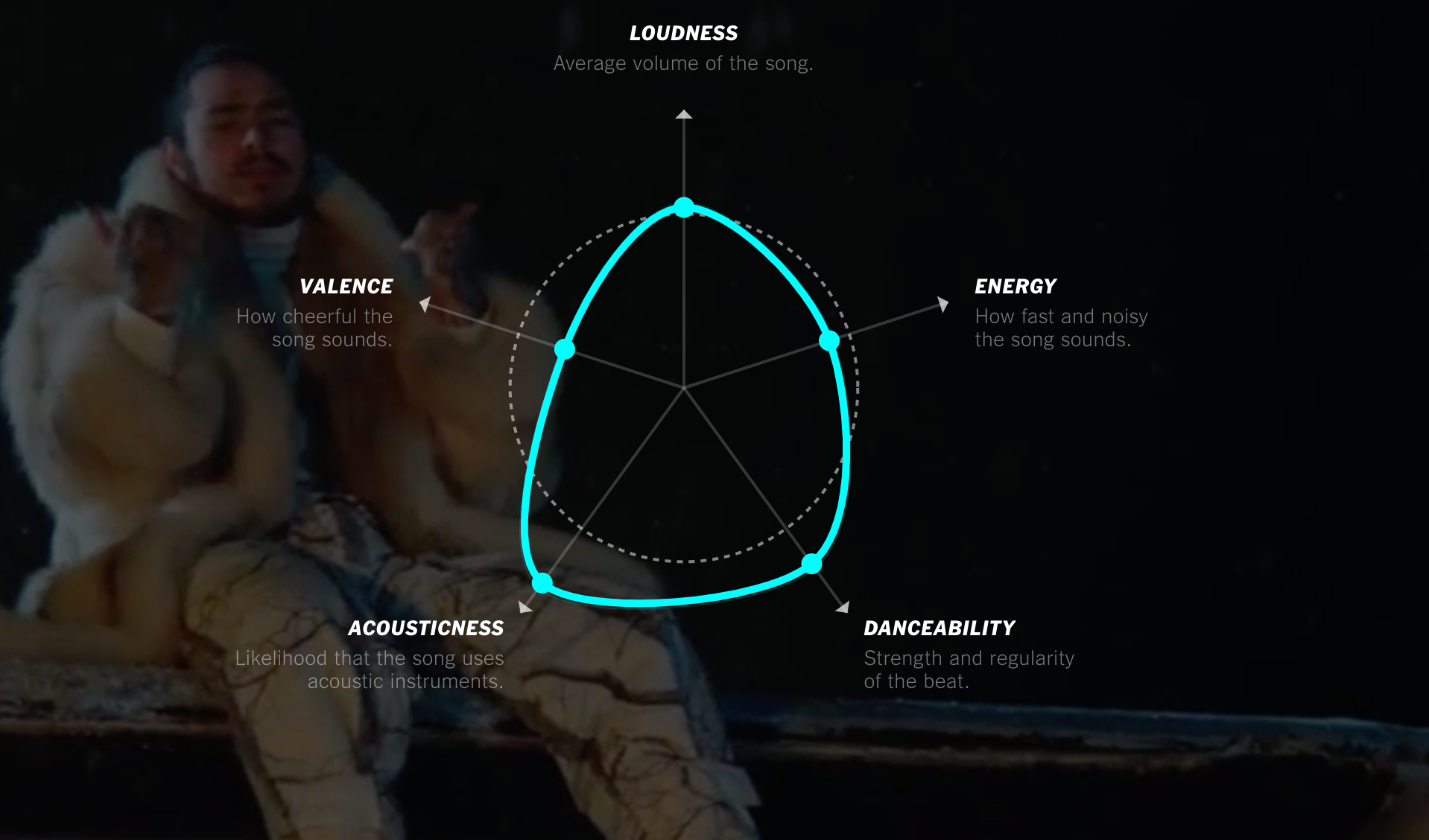
Неоднозначный, но занятный анализ летних хитов с 1970-х до 2018-го:
Автор «раскладывает» композиции по выбранным шести характеристикам-векторам и, сравнивая профили между собой, делает вывод о том, что музыкальное разнообразие в 2000-х практически отсутствует. К методологии много вопросов: почему только летние хиты, почему именно эти вектора и именно шесть, насколько субъективны и измеряемы оценки по шкале «акустичности» и «весёлости», но в целом интересная идея и качественная реализация.
Шедевральное полотно с анализом работ Пабло Пикассо:
Создатели визуализации выделили 12 ключевых тем творчества художника, разделили более чем 8000 произведений по темам и подтемам, на большом холсте разметили области, форма которых напоминает стиль художника, а площади пропорциональны количеству работ по теме, и закрасили области масляными красками. Получилась впечатляющая полутораметровая картино-грамма.
Сценические костюмы Дэвида Боуи в формате дополненной реальности:
Экскурсию по сценическим образам музыканта на примере четырёх феерических костюмов, конечно, сложно назвать визуализацией данных в классическом смысле слова. Но такой плотностью информации (форма, крой, материалы, детали, текстура ткани, которую, кажется, можно пощупать), как на этих 3D-моделях, может похвастаться далеко не каждая визуализация.
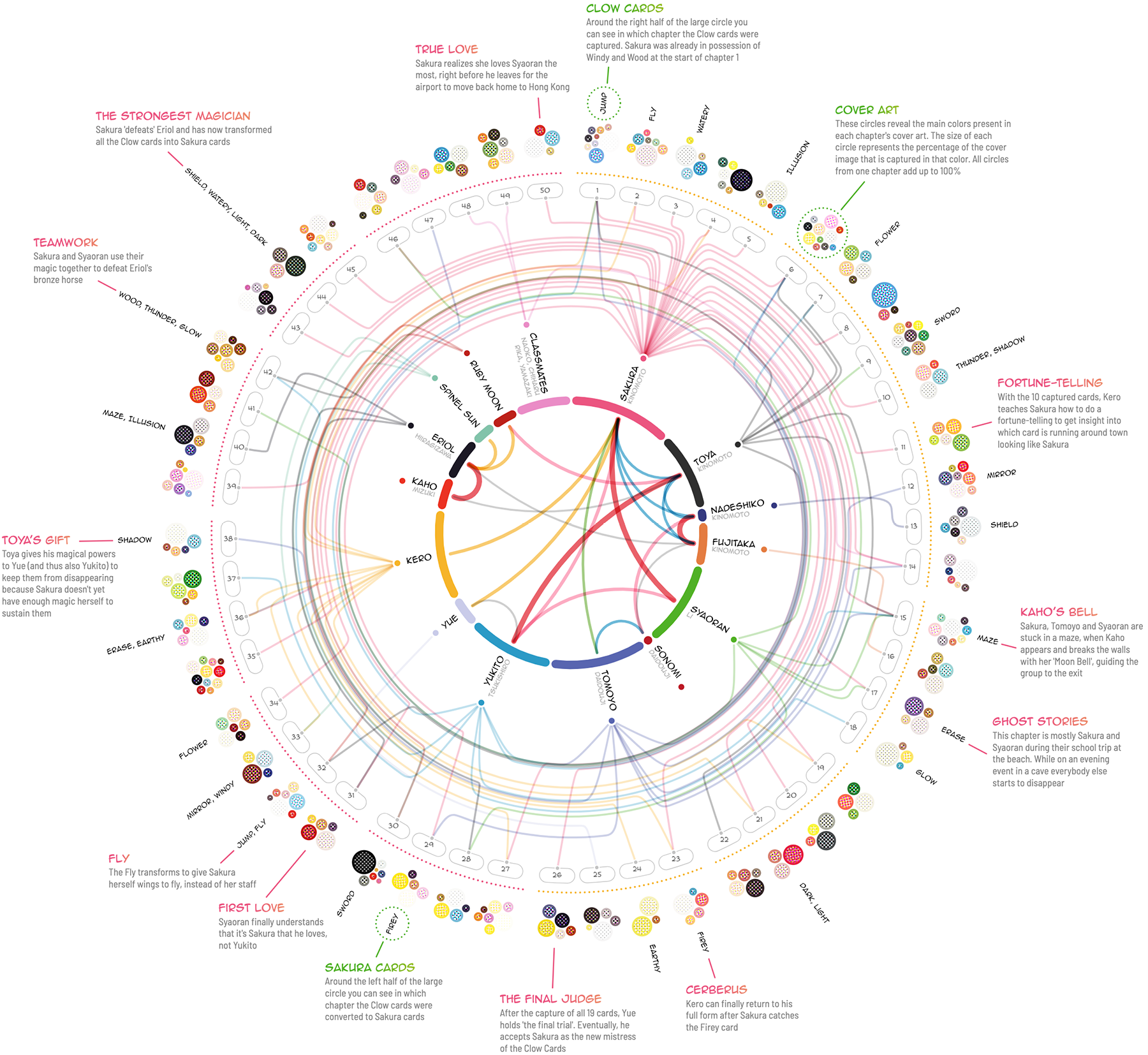
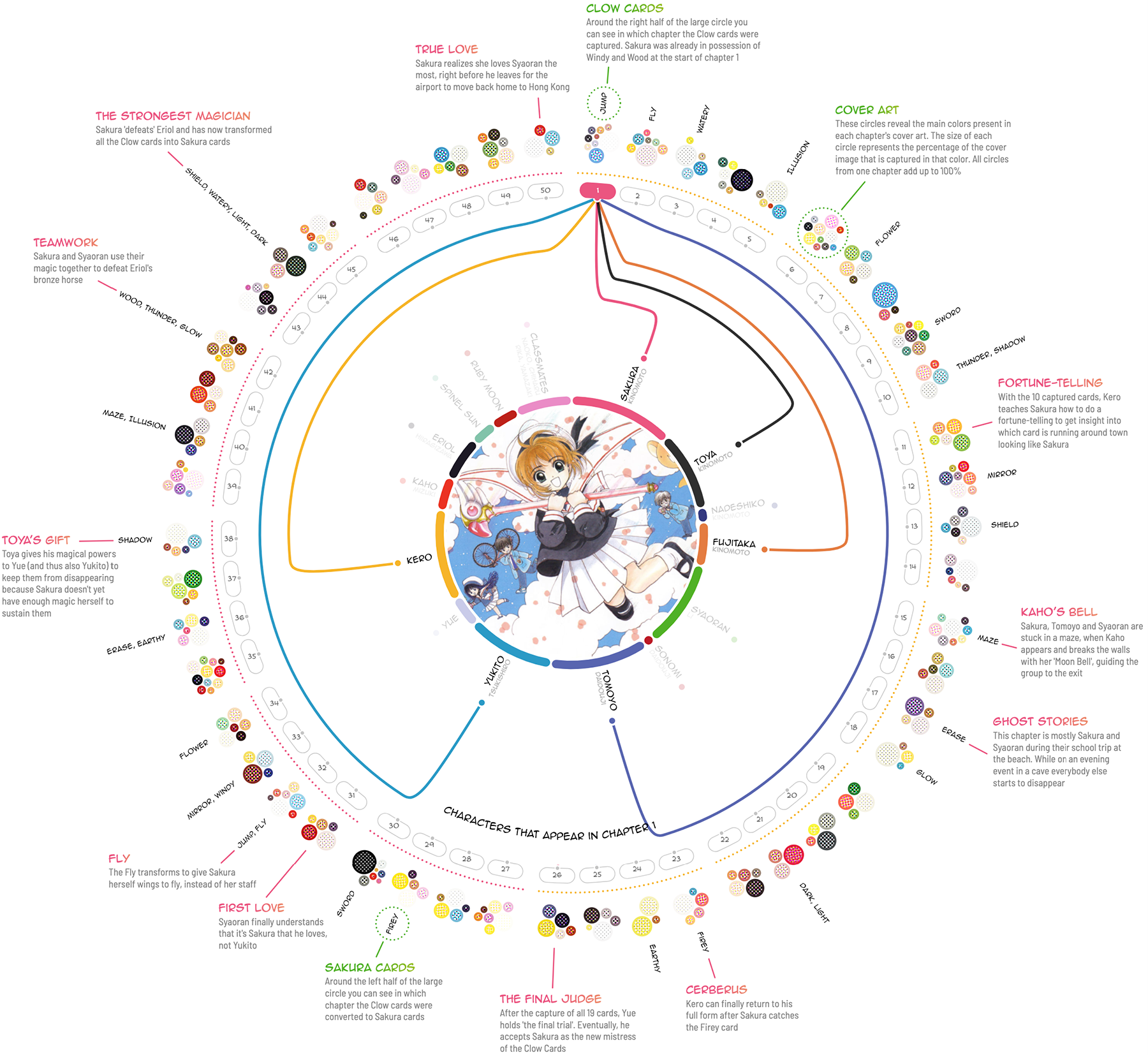
Вселенная пятидесяти глав манги «Кардкэптор Сакура»:
Я не очень люблю такой закрученный по кругу формат, но здесь много приятных деталей и видно, что визуализация сделана с любовью к теме, а это, пожалуй, самое главное ❤️
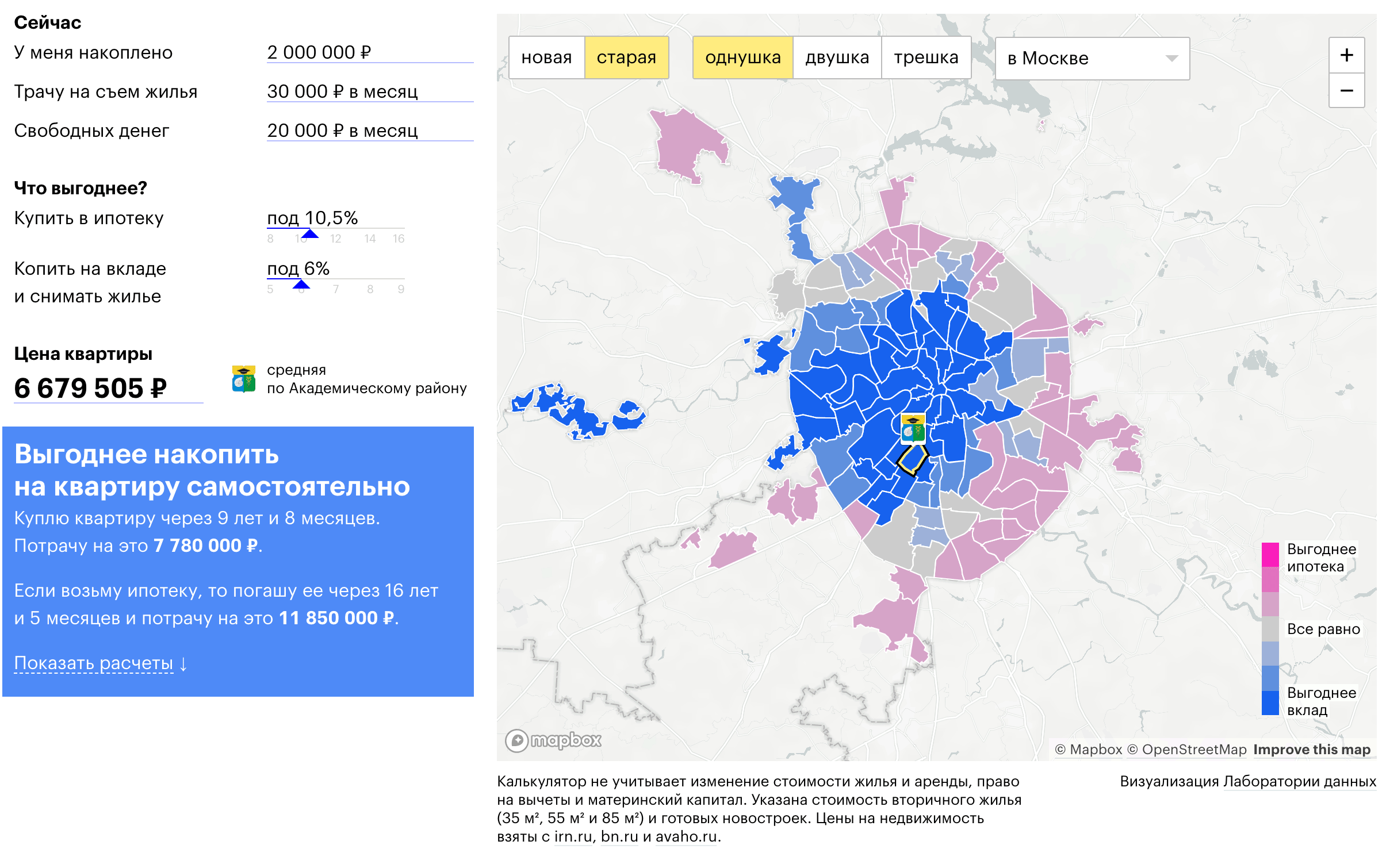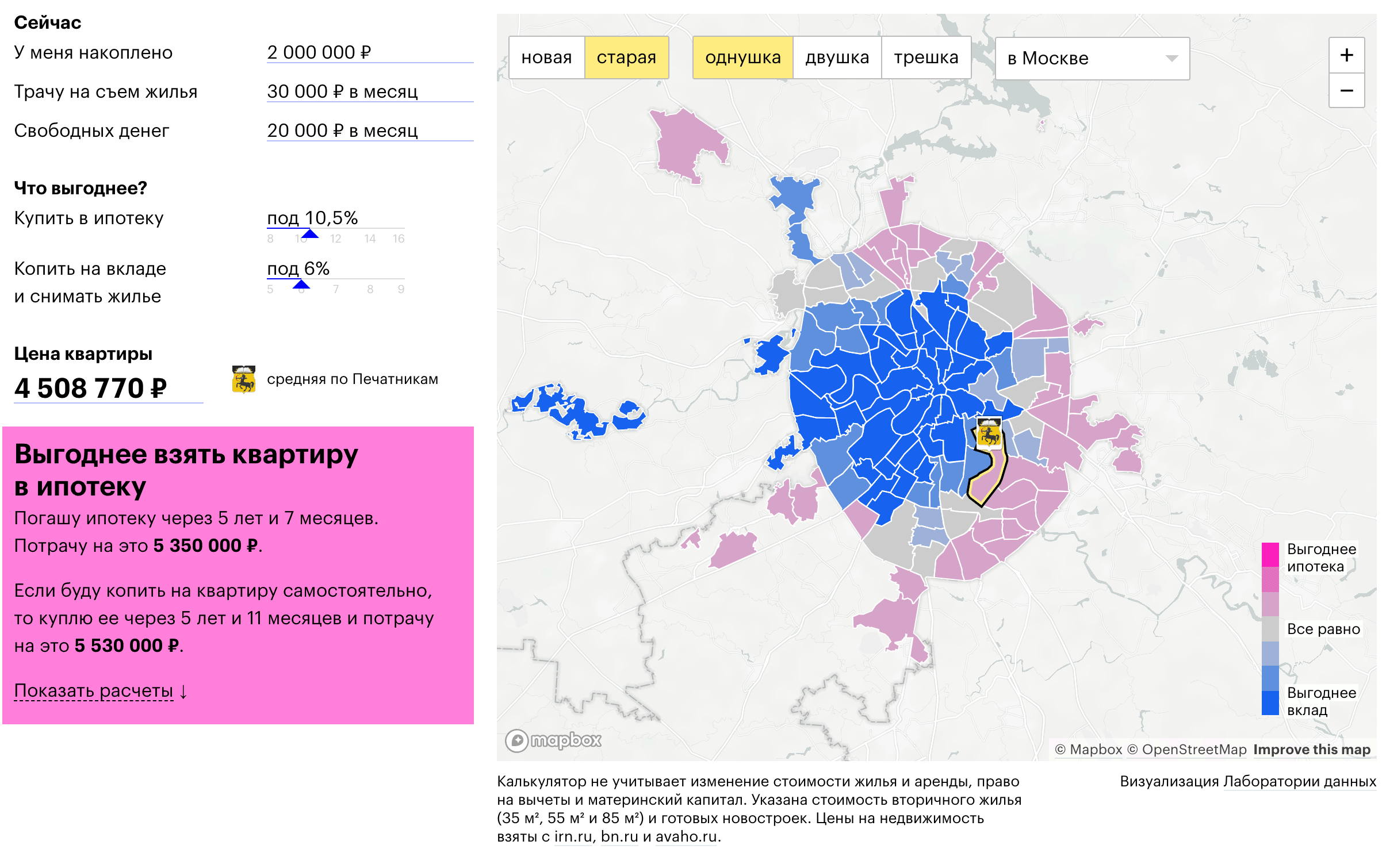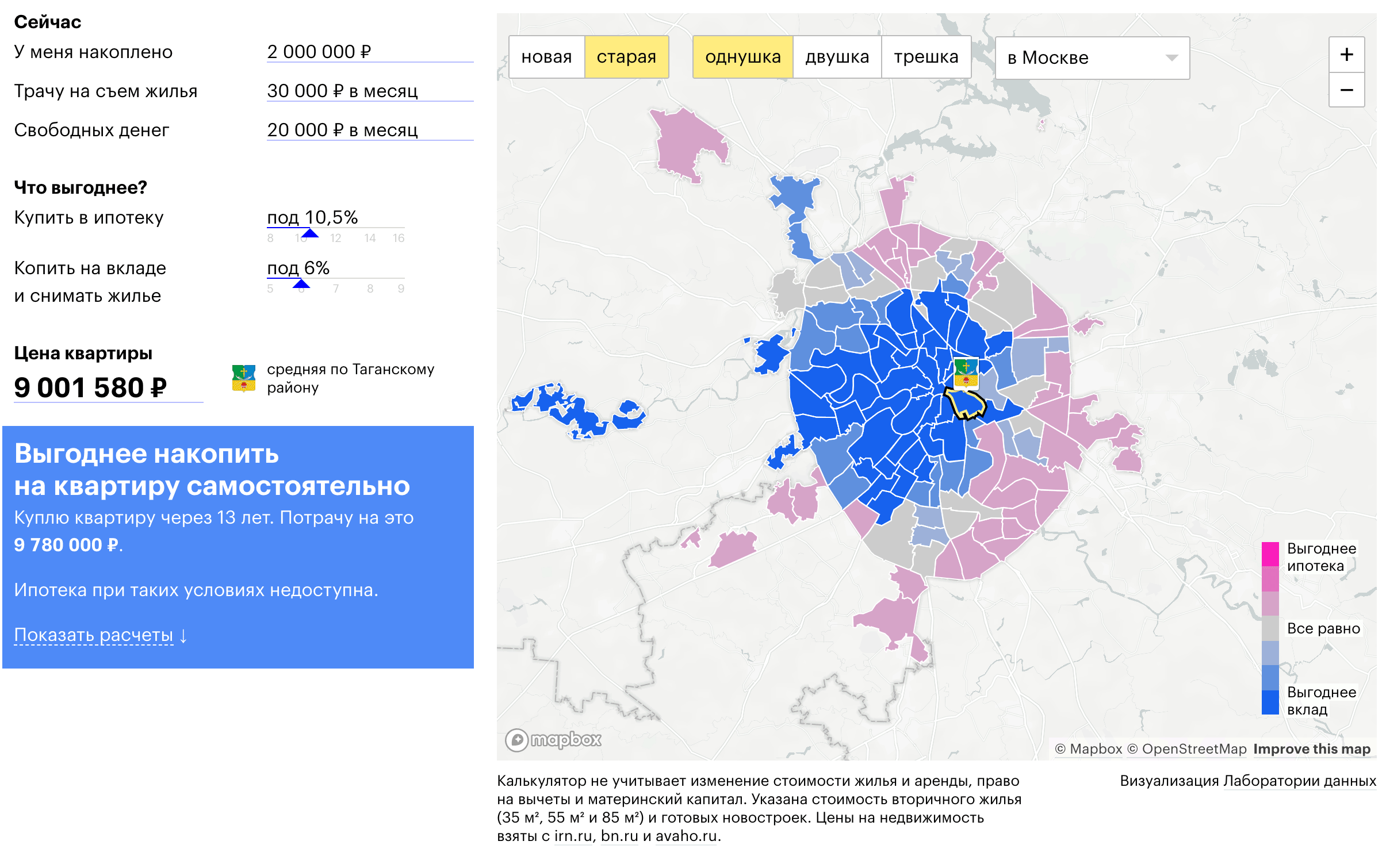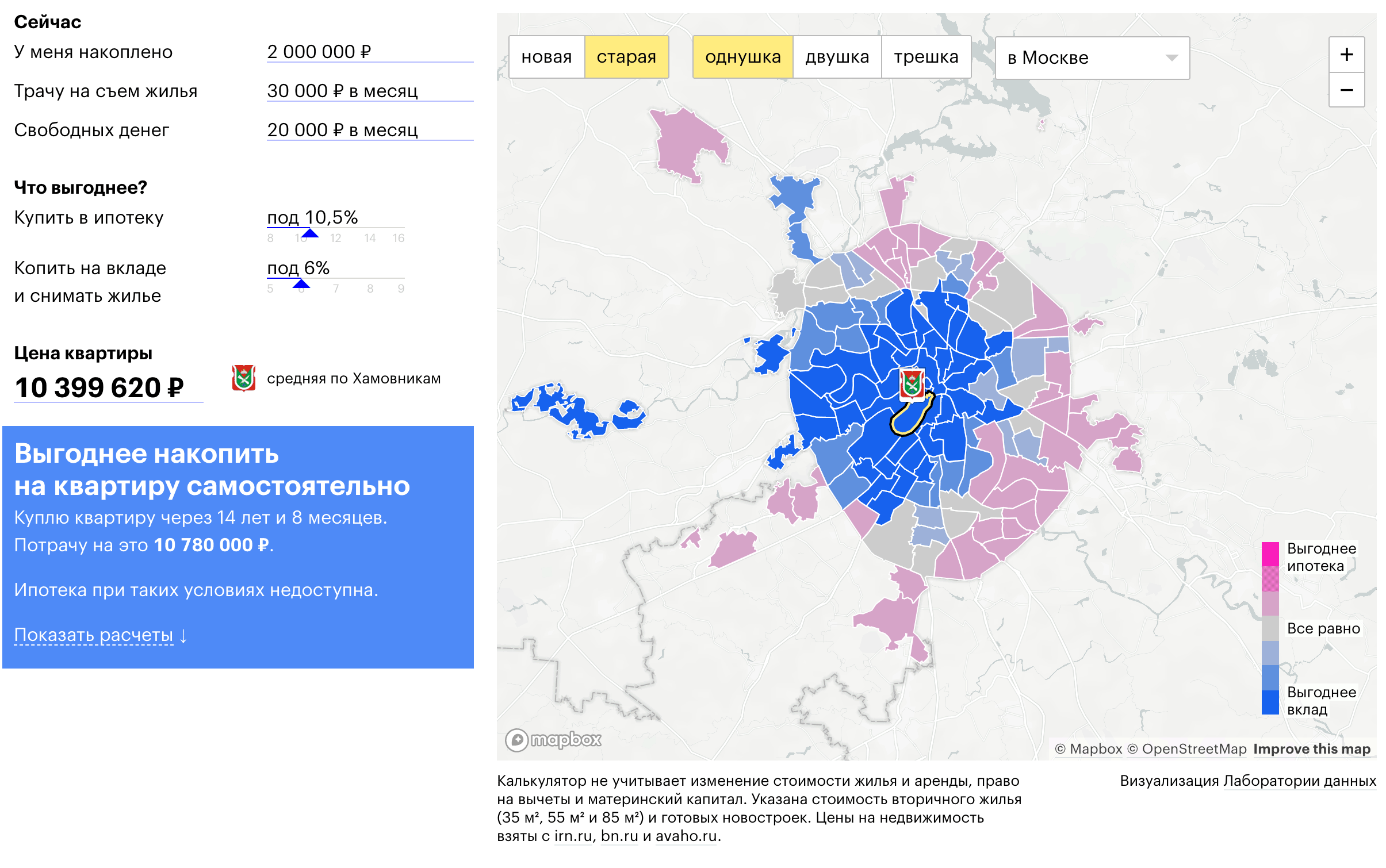
В заключение, не могу не поделиться нашей коллаборацией с «Т—Ж»:
На оcнове указаных пожеланий, возможностей и ограничений, калькулятор рассчитывает выгодный для пользователя сценарий покупки квартиры в Москве: снимать и копить или взять ипотеку.
В этом году помимо отдельно стоящих визуализаций было много историй, расследований и просто статей, в которых интерактивная графика встречалась много раз по ходу повествования. При этом в лучших примерах на один материал приходилось сразу несколько уместных, качественных и продуманных визуализаций. Кроме того, активно используются 3D-модели и дополненная реальность, которые из инструментов «вау-эффекта» превращаются в полезных рабочих лошадок. Наблюдать эти изменения приятно.
Для тех, кто интересуется — подборки прошлых лет: 2017, 2016, 2015.