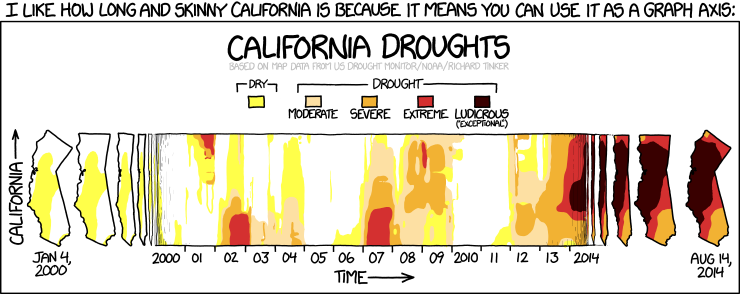
Команда «Джобоун» ведёт классный блог, в котором публикует визуализацию собранных браслетами данных. Недавний пример — ритм жизни разных городов мира, на основе сна и перемещений жителей. Как сделать визуализацию ещё интереснее?
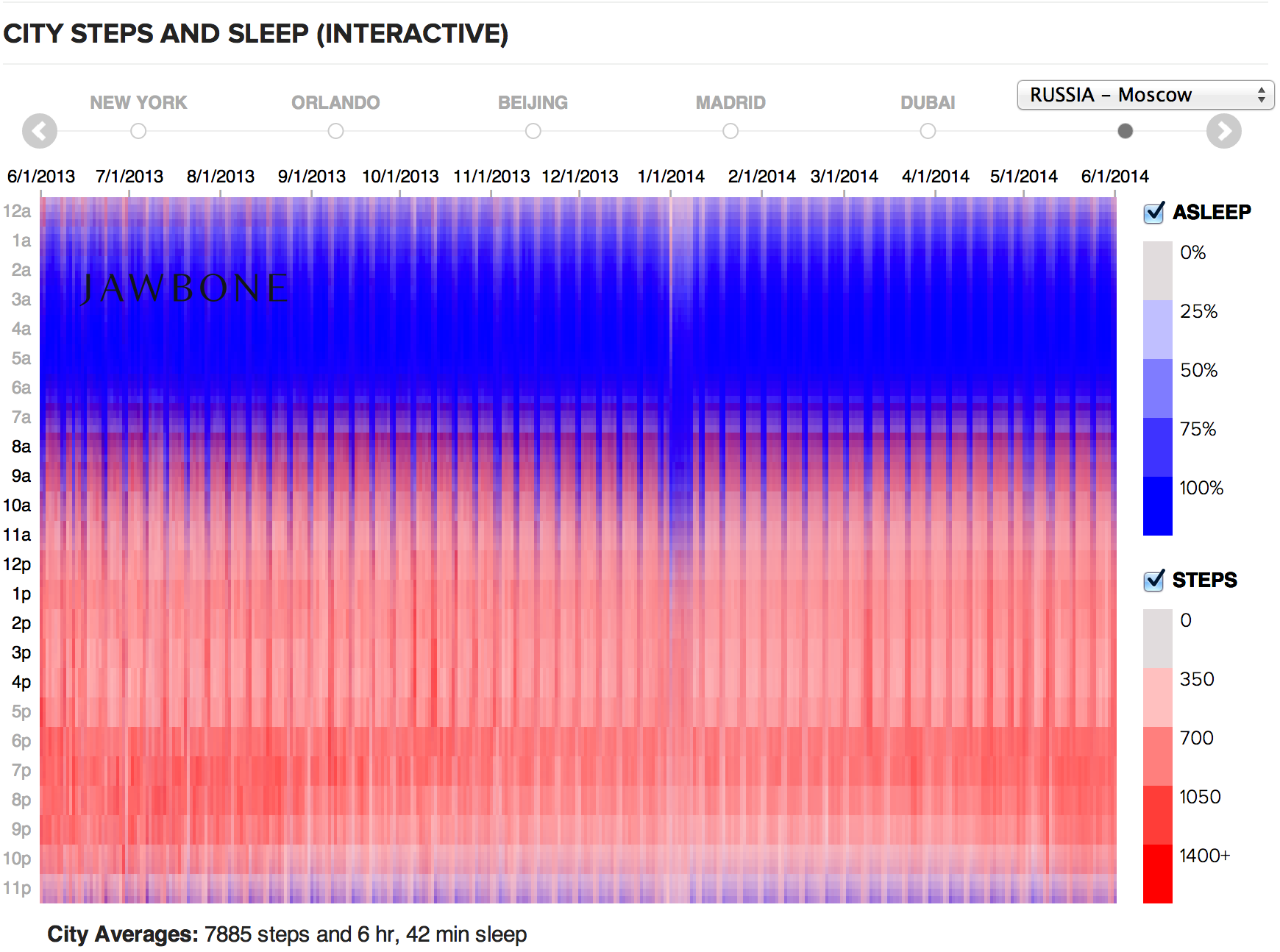
Текущий подход позволяет в деталях изучить годовую историю каждого города — так называемый микроуровень, но не показывает общей макро-картины. Погрузившись с головой в детали, мы упускаем из виду много интересного.
Для начала, посмотрим, как связаны средняя подвижность жителей и количество сна:
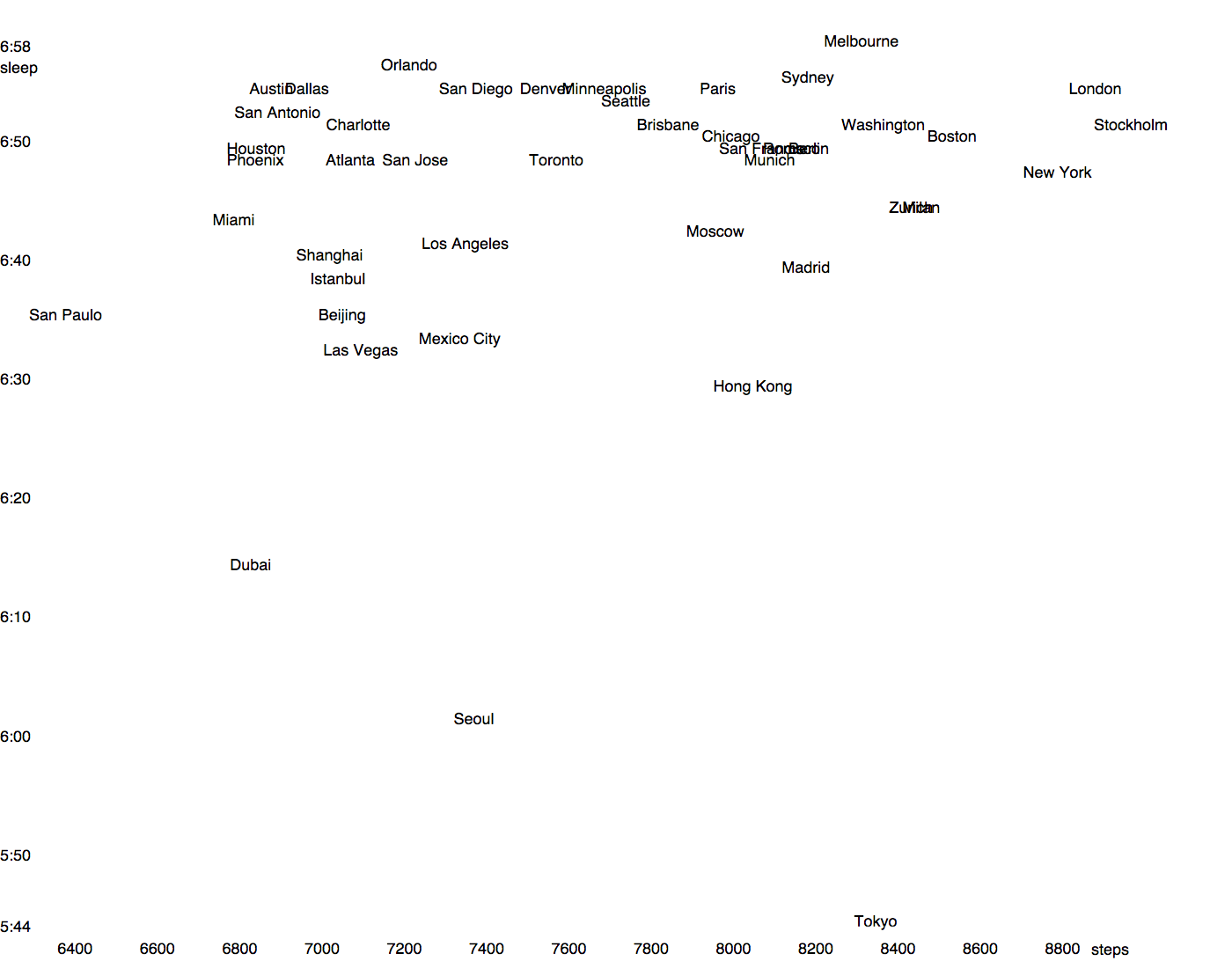
Разместив города на простом двумерном графике, мы увидим, что привычки жителей заметно отличаются между собой. Сразу бросается в глаза Токио, который в среднем спит почти на час меньше других городов. Мельбурнцы, напротив, самые большие сони. Самые малоподвижные люди живут в Сан-Паулу и Дубае, самые мобильные — в Стокгольме, Лондоне и Нью-Йорке (при этом все три города довольно долго спят). Очень близки по ритму Берлин, Рим и Сан-Франциско, а также Милан и Цюрих: на графике они буквально «слиплись».
Сравним теперь узор будней и выходных в разных городах, вычислив среднегодовую неделю:

На диаграмме выделяются бизнес-центры с чёткой границей будней-выходных (Бостон, Нью-Йорк, Вашингтон) и города-курорты (Остин, Лас-Вегас, Майами), где все дни похожи друг на друга. Заметно «скачут» горизонтальные уровни: пробуждение, обед, конец рабочего дня. Видно, что стокгольмцы освобождаются с работы раньше всех, а жители Сан-Паулу на выходных любят поспать до обеда.
Попробуем объединить эти способы отображения с исходной диаграммой и добавить интерактивную связь. Теперь наведение на город управляет диаграммой, мы можем быстро переключать годовые истории: не только изучать каждую в отдельности, но и сравнивать их между собой. Плавно переключаясь между городами, мы видим глобальные изменения и самые тонкие отличия в узорах городских ритмов.
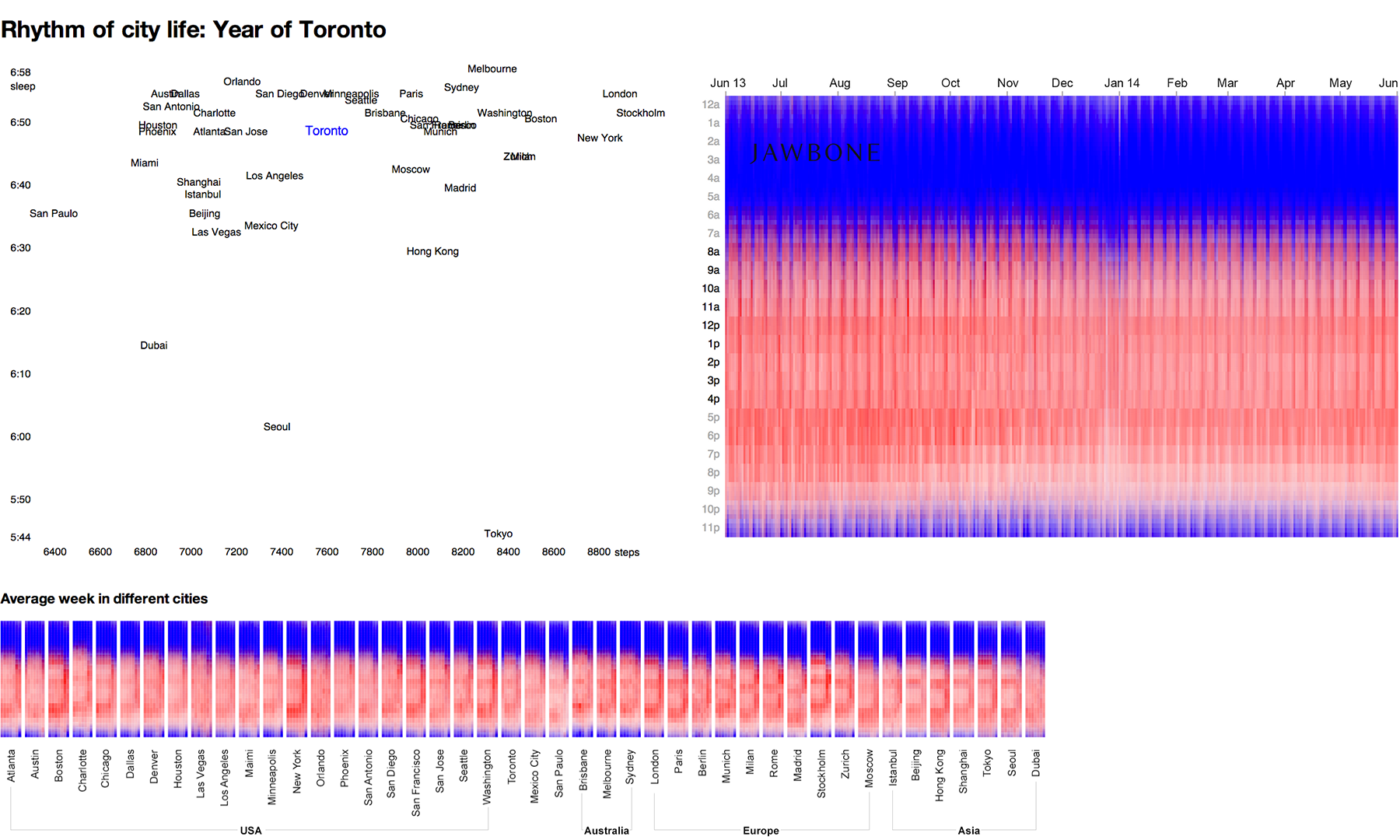
Живой прототип: http://jawbone.datalaboratory.ru/
Микроуровень интересен сам по себе, но лишён основы для всеобъемлющего изучения данных. Авторы исходной визуализации решают эту проблему текстовыми пояснениями и подсказками. Добавив макроуровень, мы увидели полную картину и получили инструмент для исчерпывающего анализа.
Присылайте вопросы о визуализации данных, организации времени, рабочем процессе, спорте и путешествиях на почту: mail@infotanka.ru. Ответы публикуются по понедельникам.