
Вопрос-ответ: о работе со сложными системами
Анонимно:
Я начинающий дизайнер и мне поручили обновить интерфейс сложной банковской системы. С чего лучше начать работу, как удержать в голове зависимости между разными элементами? Таблицы и списки, кажется, только сильнее запутывают.
Представьте, что перед вами гигантский паззл. Вы можете сначала рассмотреть и классифицировать все кусочки, а потом приступить к сборке. Или взяться за небольшой фрагмент, собрать его, перейти к следующей тематической горстке, и так, пока «слепых пятен» почти не останется.
В работе над сложными системами я придерживаюсь второго пути: начинаю с относительно небольшой, но важной задачи, досконально разбираюсь в ней, предлагаю решение и довожу его до внедрения. Один хороший интерфейс в системе — это уже польза, а в качестве бонуса я получаю близкое знакомство с частью системы и плюс в репутацию. Чем больше таких готовых фрагментов, тем более полная картина складывается в голове, тем более сложные и комплексные задачи я готова решать. Ничего страшного, если после «вскрытия» очередного пласта какие-то из ранних решений придётся пересмотреть, к тому времени они уже принесут пользу.
Я всегда ставлю задачу самостоятельно. Обсуждаю проект с ответственными лицами, разбираюсь, задаю вопросы, после чего формулирую задачу своими словами в 2-3-4 абзаца текста. В «Нет-крекере» я периодически сталкивалась с длинными ТЗ, но мне всегда удавалось договориться о живом обсуждении и ни разу не пришлось тратить время на изучение многостраничной документации.
Во время работы над задачей я «загружаю» всю доступную информацию в мозг и даю ей «повариться», пока решение не будет готово. После этого я «выгружаю» готовый фрагмент (фиксирую решение в виде картинок с пояснениями, например, в бейскемпе) и готова приступать к следующей задаче. Пока я ищу решение, я не берусь за другие проекты, не участвую в обсуждениях и встречах, не относящихся к теме. Входящая информация по другим задачам копится в почте и ждёт своего часа.
Резюме
Не пытайтесь объять необъятное, начните с быстрых побед. Ставьте задачу сами, избегайте формальных ТЗ. Сохраняйте фокус, работайте над одной задачей в один момент времени. Фиксируйте результаты для быстрого доступа в будущем. Постепенно собирайте «большую картину» из качественно проработанных фрагментов.
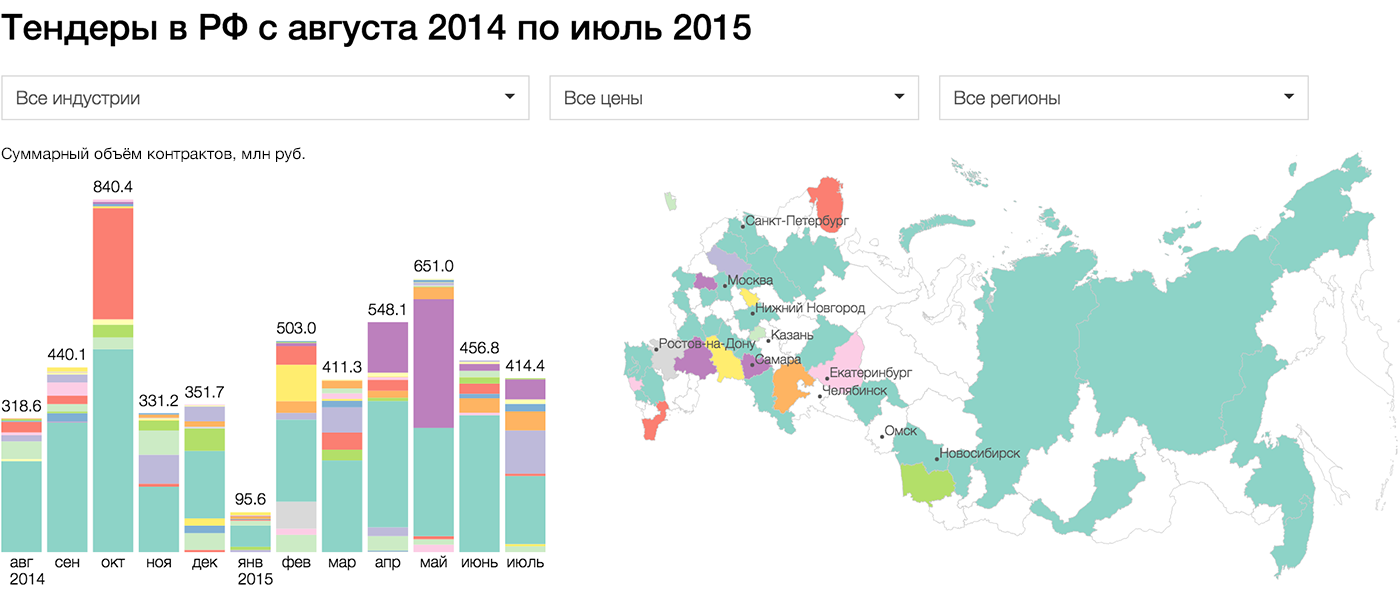
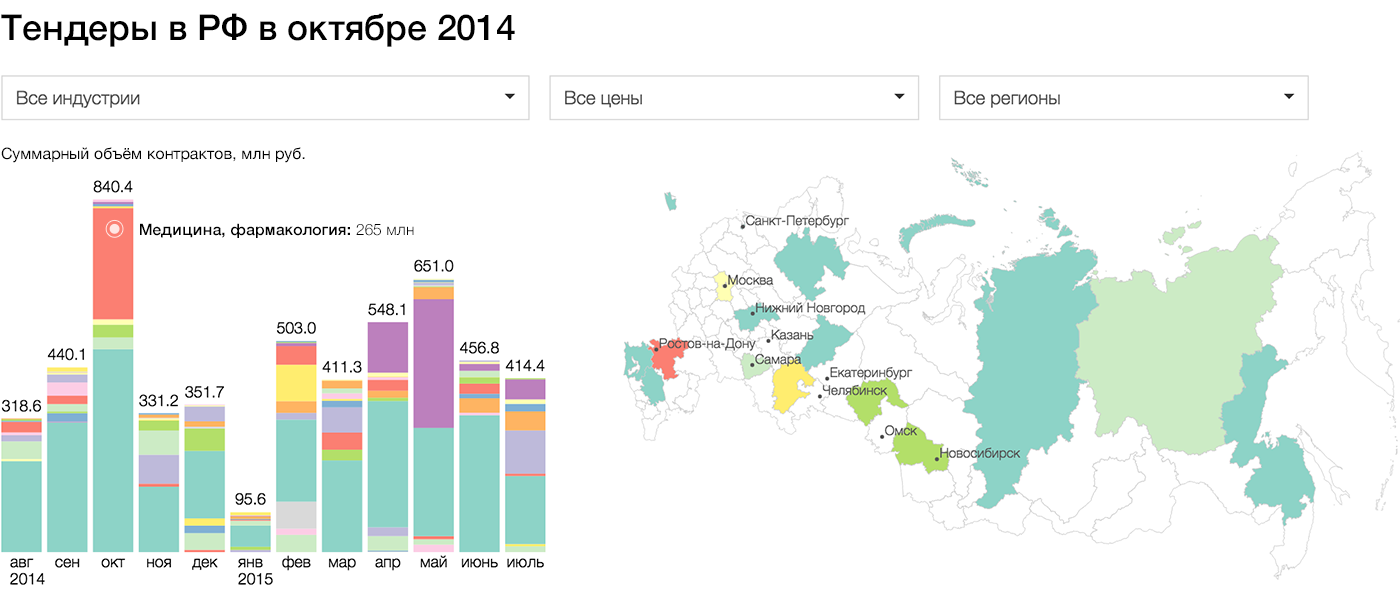
Подробный рассказ о моём опыте работы со сложными системами в «Нет-крекере», 2011 год:
Присылайте вопросы на почту data@datalaboratory.ru — о визуализации данных и не только.





{kind=link}