Алгоритм Δλ: элементарные частицы данных
Физика выводит законы макромира и свойства материи, изучая элементарные частицы, их характеристики и способы взаимодействия. Физики издавна ставили эксперименты и фиксировали закономерности, но только знания о молекулах, атомах, субатомных частицах, фермионах и бозонах позволили докопаться до сути наблюдаемых явлений.
Визуализация показывает и объясняет реальность данных так же, как физика описывает реальность нашего мира. Чем глубже визуализация погружает зрителя в данные, тем лучше он понимает суть происходящего.
Вот типичный интерактивный бизнес-отчёт:
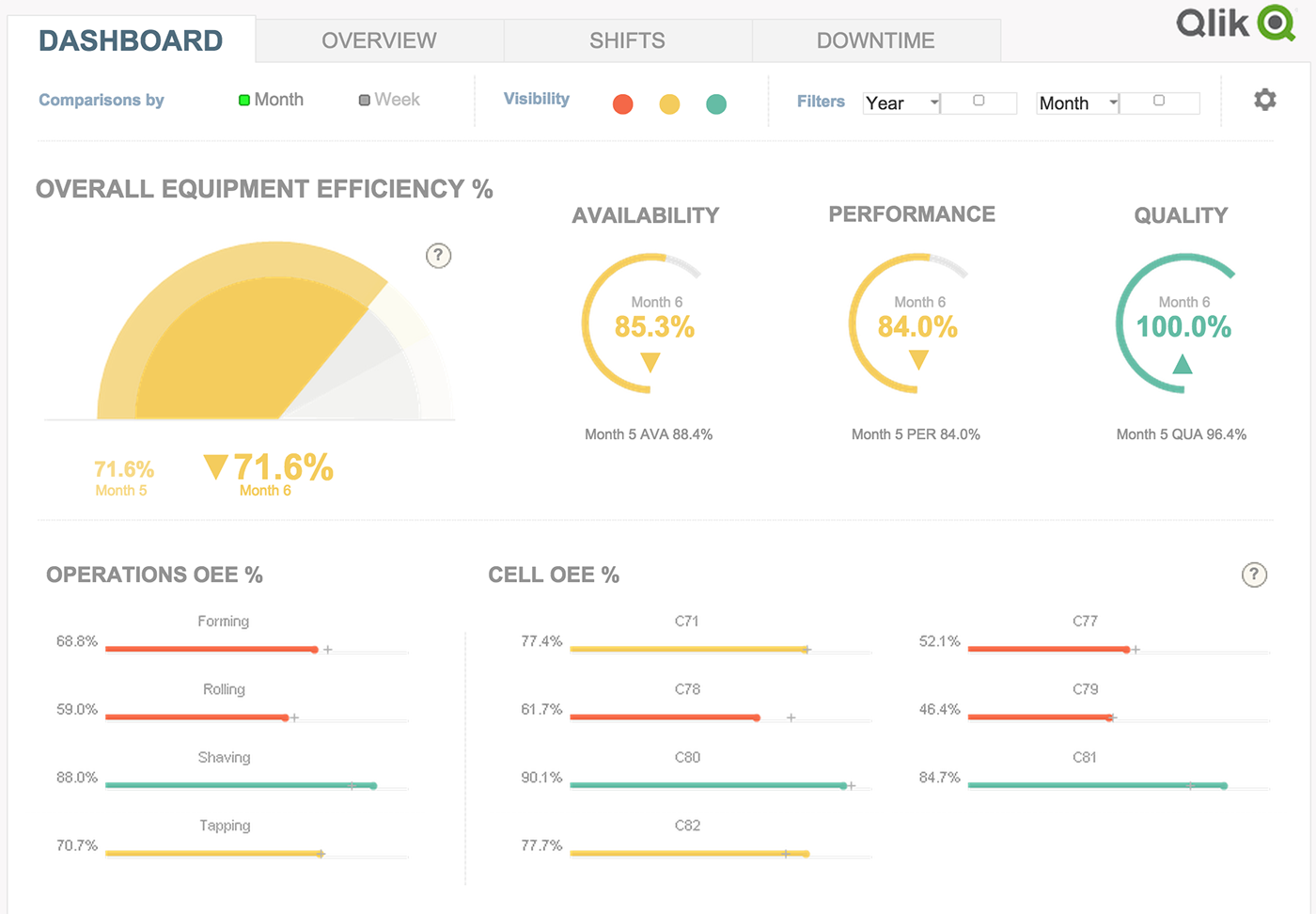
Визуализация нескольких усреднённых параметров показывает положение дел, но не объясняет почему эти цифры таковы, что на них влияет и что можно улучшить. В приведённом примере нет живой массы данных, только застывшие, расчитанные внутри системы срезы. Попробуем взглянуть на задачу иначе: представим реальность данных, в которой завод выпускает продукцию. Каждый день производство отгружает тонны масла и сопутсвующих продуктов с некоторой долей брака, бригады сменяют друг друга, машины простаивают из-за отсутствия сырья, ломаются, проходят плановое техобслуживание. Данных и сущностей так много, что кажется, что показать их все на одной визуализации невозможно.
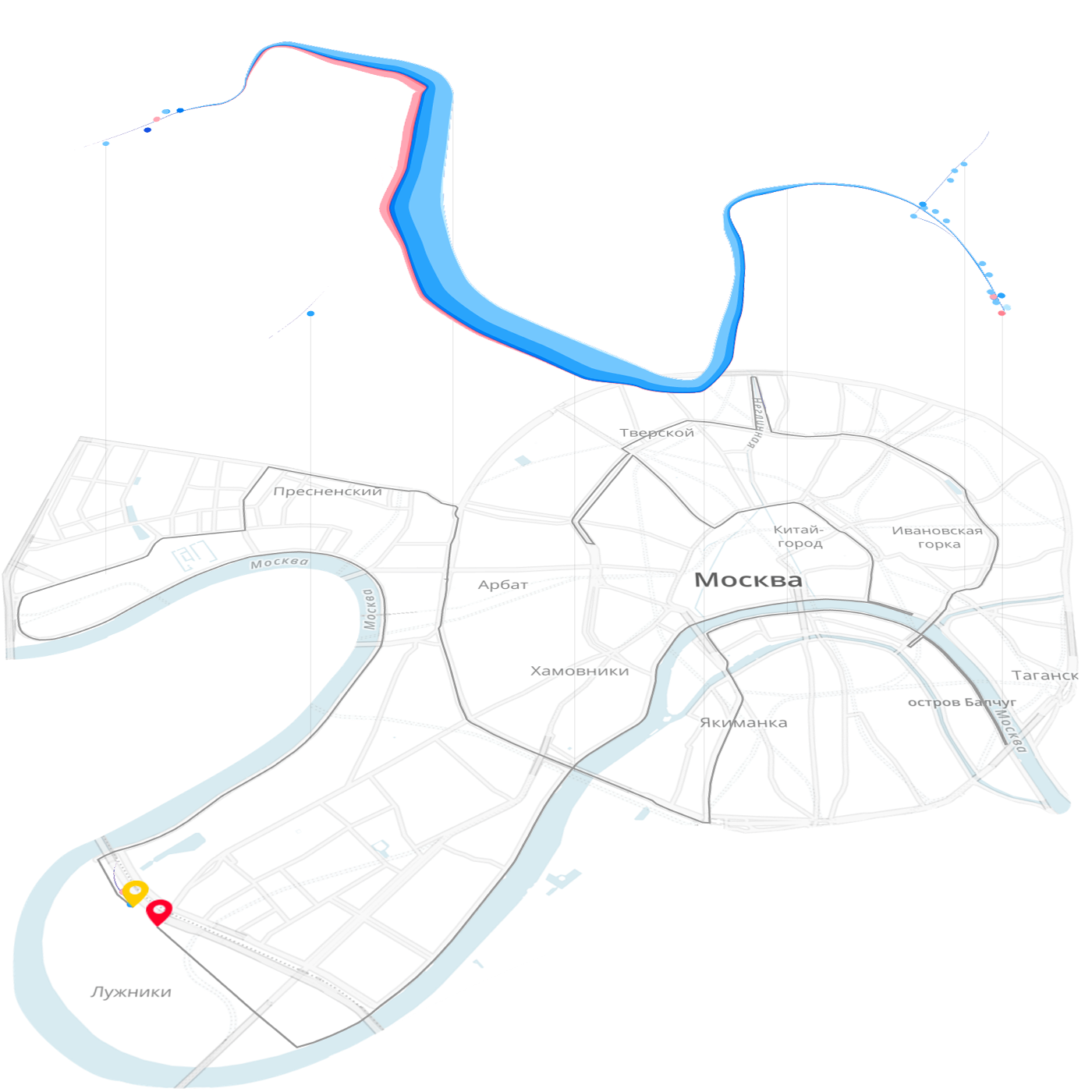
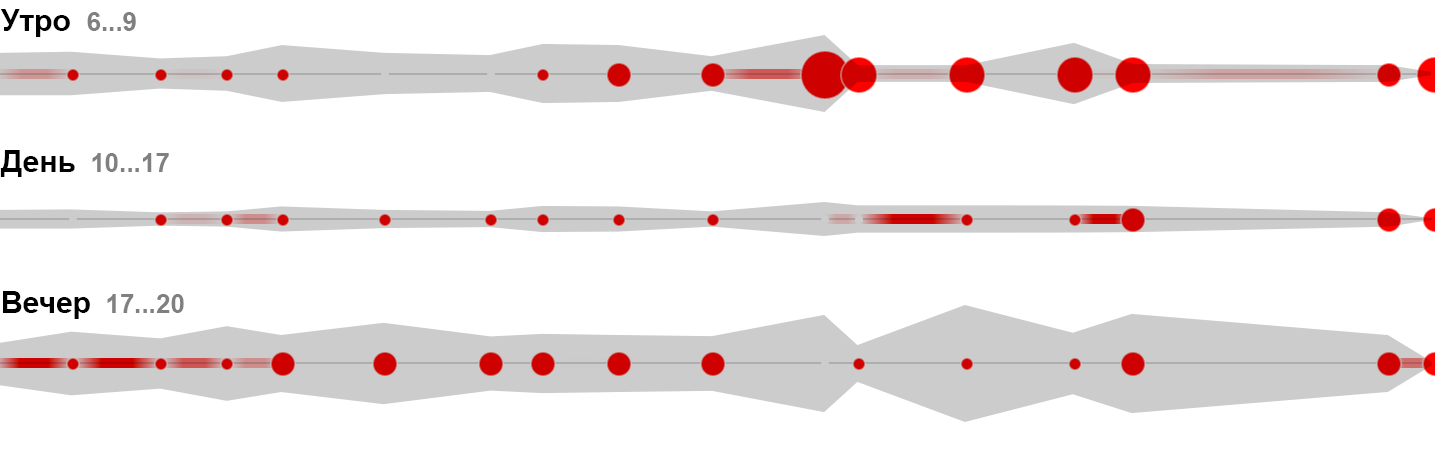
Последуем примеру физиков и постараемся выстроить общую картину из элементарных частиц. Частицей будет тонна продукции, выпущенная конкретной машиной, расположенной в конкретном цеху, во время работы конкретной бригады. Выделенная частица сама подсказывает своё визуальное воплощение: тонну продукции закодируем чёрточкой единичной толщины, её цветом — качество «норма/брак». Из частиц соберём следующую осмысленную визуальную единицу: результат работы за час, смену, сутки и т. д.

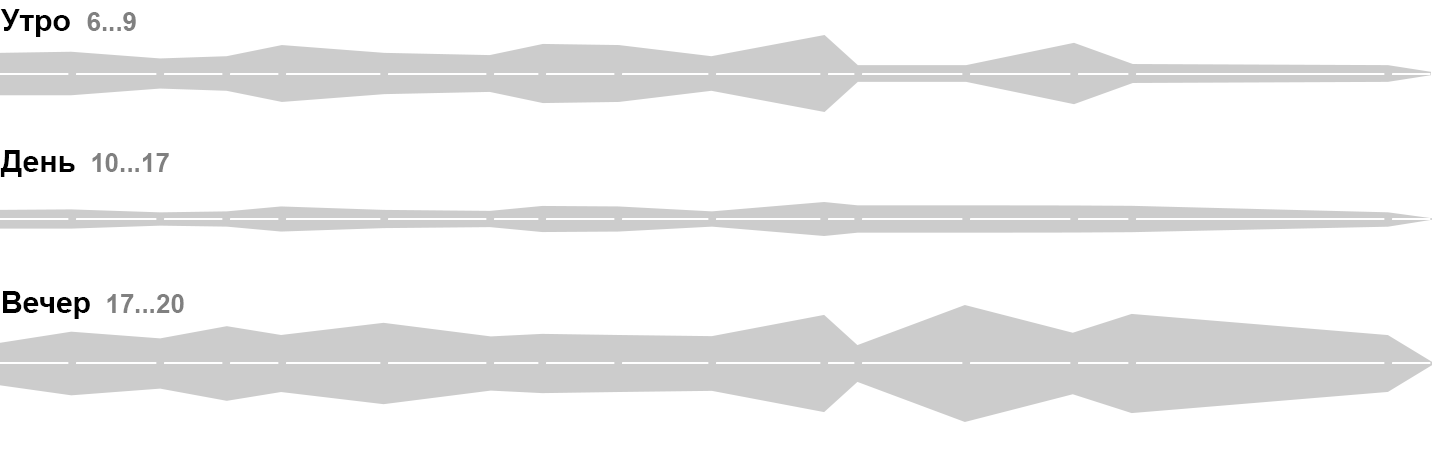
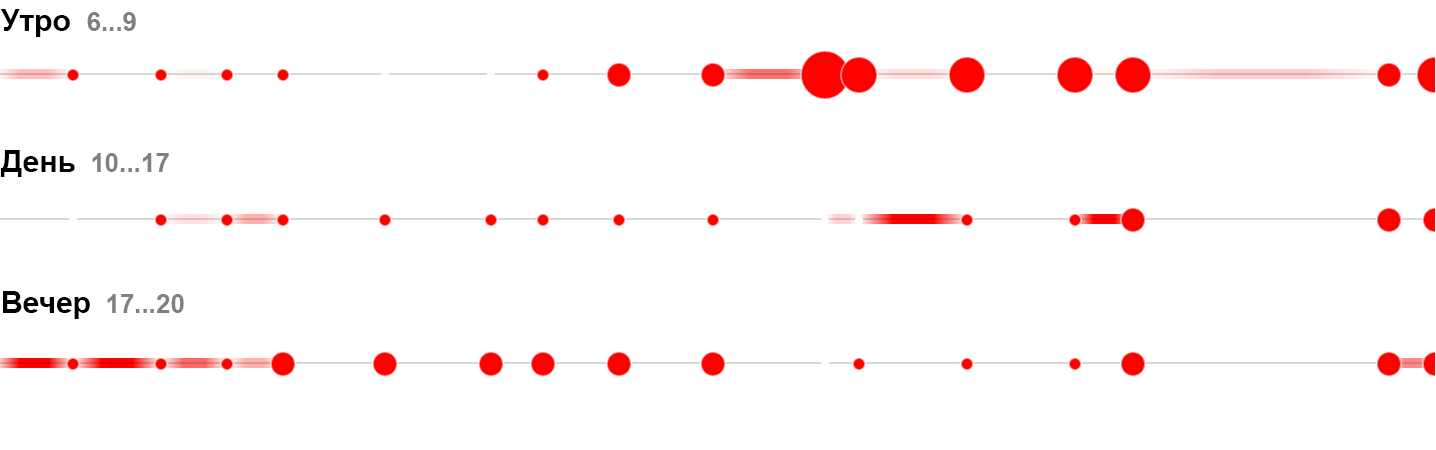
Во временной развёртке появляется ещё один тип частиц: часы простоя. Их суть и визуальное обозначение — дыра в производительности. Разные причины простоя закодируем цветом «дыры». Вот как выглядит результат дневной работы одной из машин:

Утром машина начала выдавать брак и пришлось потратить несколько часов на ремонт, ещё час она выходила на рабочий режим, после чего её производительность стала отличной. Эффективность за день получилась всего 22% из-за плохого старта.
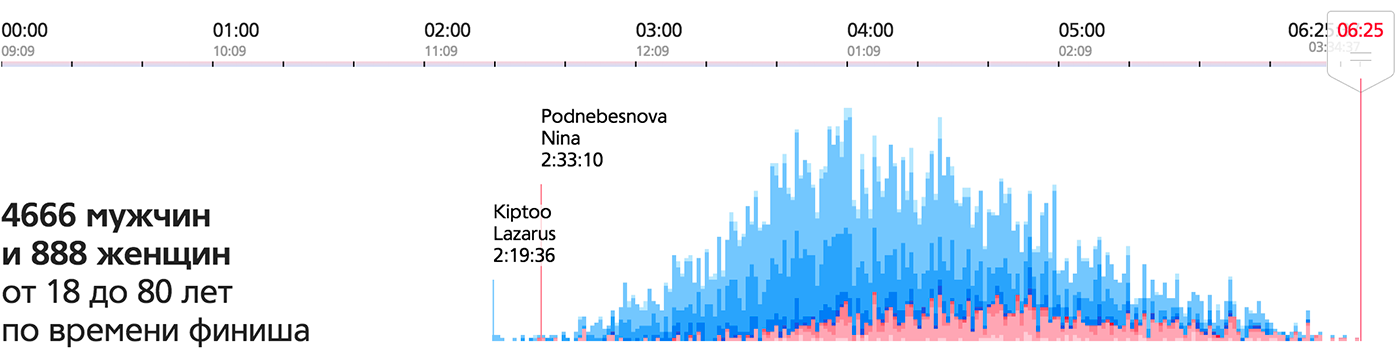
Суммируя элементарные частицы получаем картину производительности машины, бригады, целого цеха и даже всего производства (при условии, что тонны суммируются с тоннами, а не с погонными метрами — в данном случае это так). Цветные дыры превращаются на общей статистике в мини-график простоев:
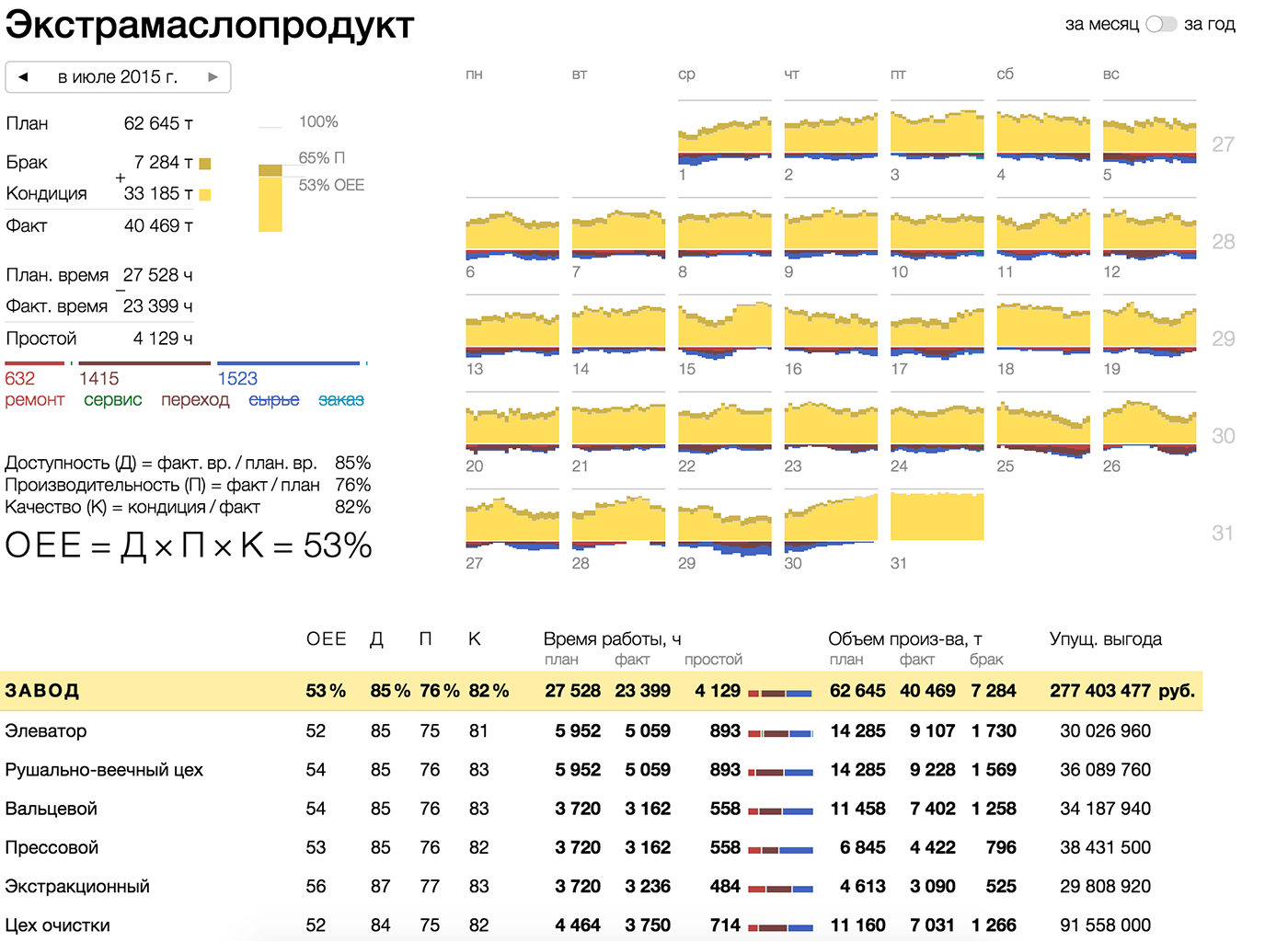
На визуализации видна общая эффективность предприятия, а также изменение эффективности во времени и разбивка по цехам (в поисках слабого звена можно спуститься по иерархии до машин и бригад). Такая визуализация выявляет проблемы и помогает повысить эффективность, а не просто констатирует факт.
Этот пример демонстрирует, как элементарные частицы делают визуализацию мощнее и глубже, и как визуальное воплощение элементарных частиц следует из их свойств и предполагаемых способов «суммирования» с другими частицами. О том, как выбирать визуальное кодирование элементарных частиц и суммировать их в общую картину я расскажу в следующих заметках.
Следующая теоретическая заметка выйдет 30 мая.