
Алгоритм Δλ: ответы на вопросы
Вопросы из зала разделю на три группы: об элементарных частицах, о каркасе и общие вопросы по алгоритму.
Элементарные частицы и визуальные атомы
Спрашивает Юлия Торгашова:
Я ломаюсь на элементарных частицах. Не могу экстраполировать на разные виды «частиц». Например, вот визуализация бюджета города, что в ней «элементарная частица» — деньги? учреждения? мероприятия? Про визуальные атомы при этом понятно.
Чтобы найти элементарную частицу нужно понимать, что искать. Элементарная частица данных — сущность достаточно крупная, чтобы обладать характерными свойствами данных, и при этом достаточно мелкая, чтобы все данные можно было разобрать на частицы и собрать заново, в том же или ином порядке.
Поиск элементарной частицы начинайте снизу вверх: ищите разные потенциальные частицы и примеряйте их к данным. «Деньги?» — хорошее начало, единица измерения бюджета, рубль, но слишком универсальная. Подойдёт, если не найдём чего-то более характерного для городского бюджет. «Мероприятия» не подходят, потому что не все бюджетные траты связаны с мероприятиями, есть и другие расходы, а элементарная частица должна описать всю массу данных. «Учреждения?» — с одной стороны, да, все бюджетные деньги можно разбить на отчисления тому или иному бюджетному учреждению. С другой стороны, это уже слишком крупная единица, ведь внутри учреждения может быть несколько транзакций, в том числе периодических. Если мы возьмём учреждение в качестве элементарной частицы, то будем оперировать только общим бюджетом этого учреждение и потеряем временной срез, а также возможный срез по целевому назначению средств.
В моих рассуждениях уже несколько раз промелькнула элементарная частица — отчисление, однократное перечисление бюджетных средств в определённом размере (те самые рубли) в определённую организацию на определённые цели (например, на мероприятия), привязанное ко времени. Отчисления бывают периодические и нерегулярные, цель может состоять из нескольких уровней иерархии: на мероприятие → на организацию концерта → гонорар исполнителя. Из отчислений состоит вся расходная статья городского бюджета, при этом отчисления можно складывать между собой, сравнивать, отслеживать динамику. Если нужно визуализировать приход бюджета, используйте частицу-близнеца — поступление. Из поступлений можно составить картину формирования городского бюджета так же, как из отчислений — картину его использования.
Попробуйте начать с низов (с единиц измерения), примеряйте на роль частицы данных всё более крупные сущности и рассуждайте, почему та или иная сущность подходит или не подходит. В рассуждениях непременно проявятся новые сущности и намёки на частицу данных. Для найденной частицы обязательно выберите подходящее слово или термин, так легче в дальнейшем думать о ней и решать задачу. Юля, пожалуйста, напишите, стало ли понятнее, и какие остались вопросы.
Спрашивает Иван Печищев:
Как соотносятся визуальная частица и частица данных? Может ли у одной частицы данных несколько воплощений в визуальных частицах? Скорее всего, да. Как они соотносятся?
В публикациях вы подробно описали визуальную сторону (пиксель, прямоугольник и т. д.). Но какой логикой я из числа (количества, расстояния и пр.) дойду до визуальной частицы? Может, элементарные частицы ввести в таблицу? Как таблица Менделеева? Чтобы было видно их отличия и схожесть. Читаешь в отдельности — понятно, сравниваешь — много похожего.
Визуальный атом — это воплощение частицы данных на экране. Одна частица данных может выражаться разными атомами. Например, путь кандидата на диаграмме «Хантфлоу» показан линией:

Мы могли бы дополнить диаграмму возрастным распределением, на котором кандидаты показаны точками:

При этом цвет частицы мы сохраняем, и разные визуальные атомы представляют одну и ту же частицу с разных точек зрения. Идея о таблице визуальных частиц — отличная, спасибо! Подумаю, как её реализовать.
Спрашивает Антон:
Я сломался после столбиковых диаграмм. Там начинается какой-то ад. Диаграмму с детскими садами вообще не понял — кажется, она прямо противоречит написанному. Либо я тупой, либо эти атомы лучше использовать с большой осторожностью :—)
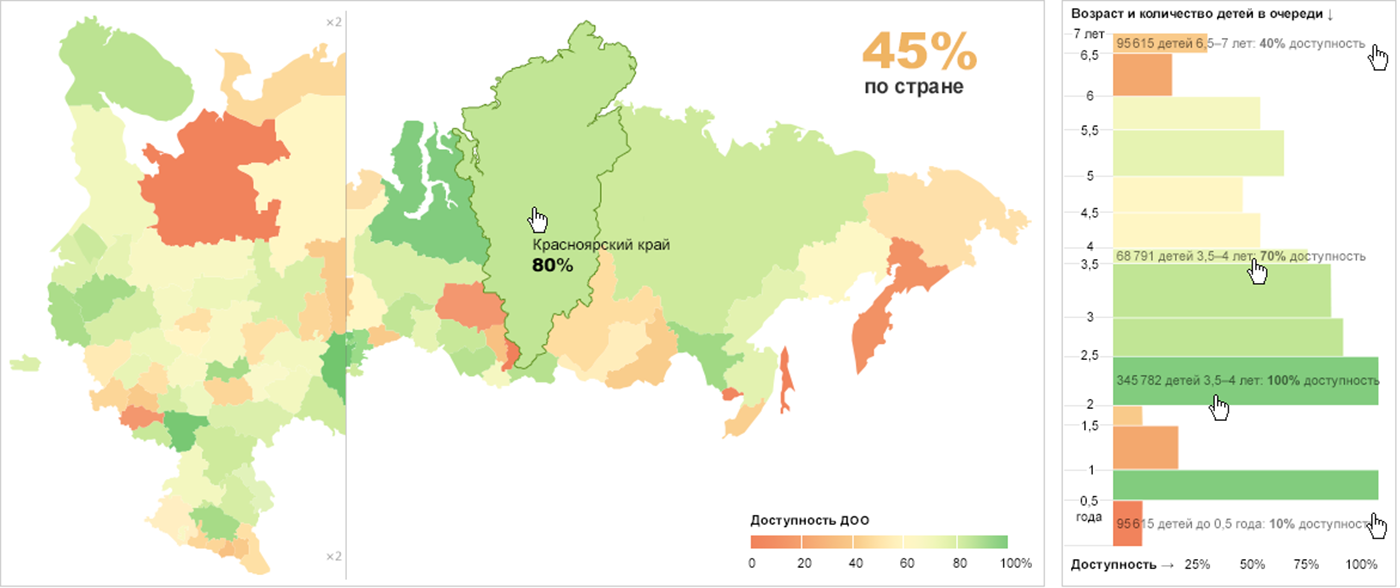
В статье речь не о формате «столбиковая диаграмма», а о прямоугольнике, как способе представления данных. У прямоугольника два линейных измерения + площадь, их производная + цвет. Прямоугольники состоят из пикселей.
На диаграмме садиков, пиксель — это ребёнок. Группируем детей (пиксели) по возрастам, получаются прямоугольные области разного размера. Чем больше детей в возрастной группе, тем больше площадь прямоугольника. Если сделать все прямоугольники одной высоты, то их ширина отразит разницу в размерах возрастных групп. Представьте детей на площадке, пусть они станут рядом с ровесниками. Получится подобие вот такой диаграммы:

Пока за кадром остался ещё один параметр (ради которого и затевается визуализация) — доступность садиков для каждого возраста. Если мы соберём всех детей в большой прямоугольник и разделим его на слои по возрастам (чем больше детей в возрастной группе, тем толще слой), то внутри каждого слоя можно будет провести границу между детьми, попавшими и не попавшими в сад. Внутри каждого слоя появится прямоугольник попавших в сад детей, высота которого пропорциональна размеру возрастной группы, а ширина — доступности садиков для этой группы, буквально, доле попавших в сад детей.
Закрашенные столбики на диаграмме — и есть прямоугольники, попавших в сад детей разных возрастов. Можно сравнить не только доступность садов для разных групп (ширину), но и количество детей попавших/не попавших в сад (площадь). Цветовое кодирование дублирует доступность, привлекая внимание к проблемам — крупным ярким пятнам.
Ландшафт и каркас
Спрашивает Денис Балуев:
Мне, как давнему читателю, понятны почти все пункты. Кроме седьмого. Перестаю понимать отличия ландшафта от каркаса. Возможно, здесь помогли бы примеры.
Спрашивает Иван Печищев:
Очень интересен процесс «схлопывания ландшафта». Тут тоже может быть разная логика и методы. Скажем, есть технический чертёж, а есть живопись или детский рисунок.
Тему ландшафта реальности данных и каркаса визуализации я раскрою в следующей заметке, там же отвечу на вопросы.
Общие вопросы по алгоритму
Комментирует Михаил Калыгин (привожу только вопросы):
У алгоритма есть жестко заданный выход — определенного вида ответы на интересующие нас вопросы по задаче, решение задачи. В зависимости от подхода к решению вход алгоритма может быть разным. С чего здесь начинать? Какие данные нам нужны для ответа? Как определять формат этих данных? Что делать, если данных нет?
Не затронут важный шаг алгоритма — предобработка данных. Так или иначе, мы не можем работать напрямую с реальностью данных. Мы можем теоретически описать эту реальность данных. Мы можем также описать элементарные частицы. Но на практике мы имеем лишь срезы реальности, гиперплоскости, грязные данные (те же таблицы). Какие из этих грязных данных нас интересуют и могут помочь нам в ответе на вопросы задачи? Как их нужно преобразовать, чтобы нам было удобно с ними работать? Какие упрощения и допущения мы можем себе позволить в рамках этой конкретной задачи? Нужно как-то грязные данные сделать чистыми и связать с элементарными частицами и визуальными атомами. Как?
В моём понимании цель алгоритма: визуализировать конкретный набор данных с максимально пользой для зрителя. Первичный сбор данных остаётся за кадром, у нас на входе всегда есть данные. Если нет данных, то и задачи по визуализации данных нет.
Данные, с которых мы начинаем работу, — это всего лишь отправная точка. После знакомства с ними, мы представляем породившую их реальность, где данных гораздо больше. В реальности данных, без оглядки на первоначальный набор мы выбираем данные, из которых могли бы сделать максимально полную и полезную для зрителя визуализацию.
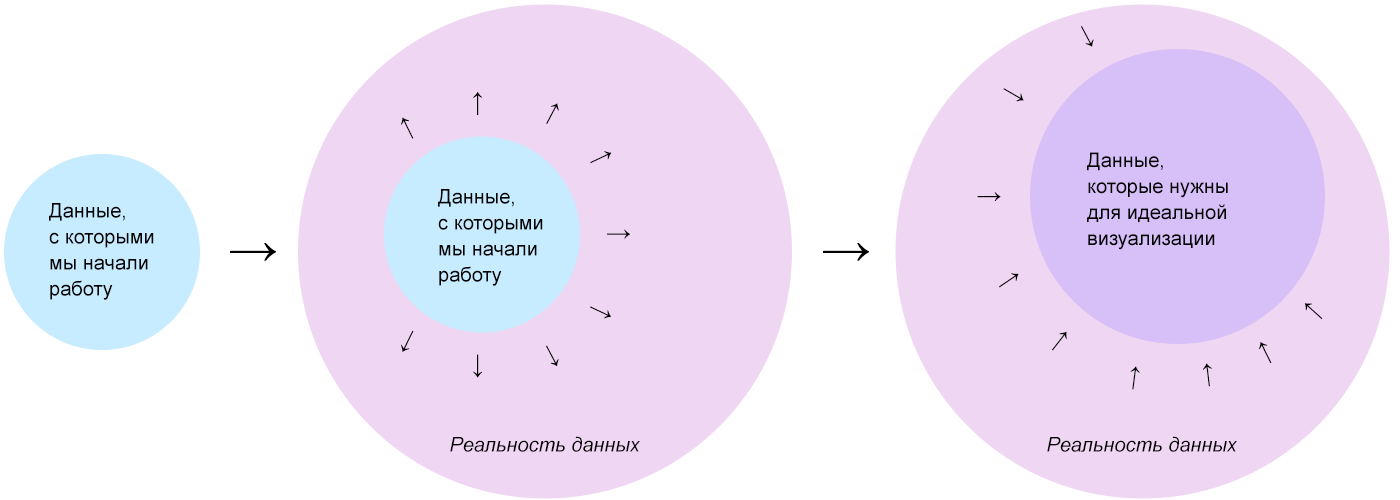
Каким будет этот набор данных для «идеальной» визуализации — зависит от сценария использования и смекалки инфодизайнера. На этом шаге лучше взять больше, чем что-то упустить. В большинстве задач уже на этом шаге вырисовывается если не вид, то основная идея визуализации.
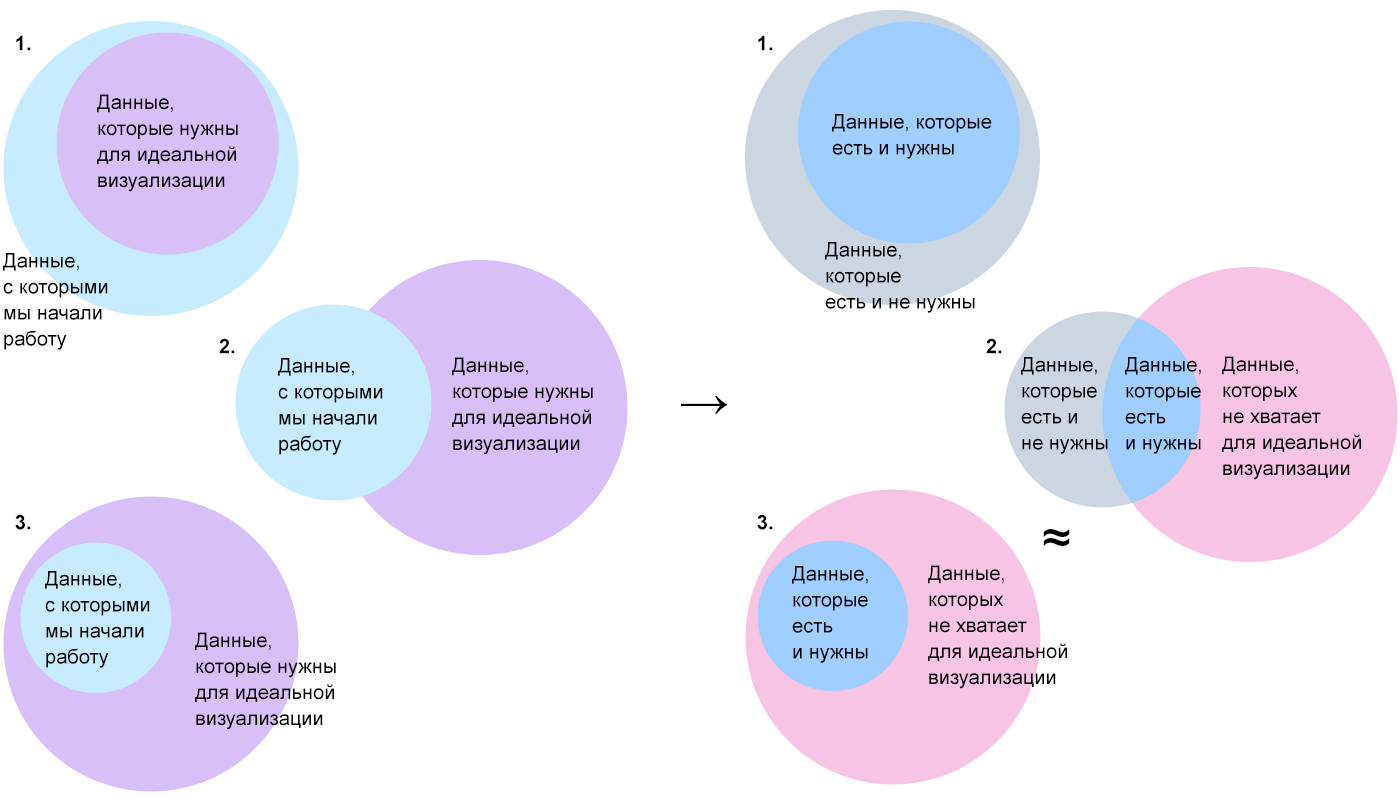
Следующий шаг — сравнить «идеальный» набор данных с тем, что мы имеем и понять, какие из первичных данных нам понадобятся, какие — нет, и какие необходимо добыть.
«Добыть» может означать найти, собрать или вычислить на основе имеющихся данных. Скорее всего доступными окажутся далеко не все данные «идеального» набора.
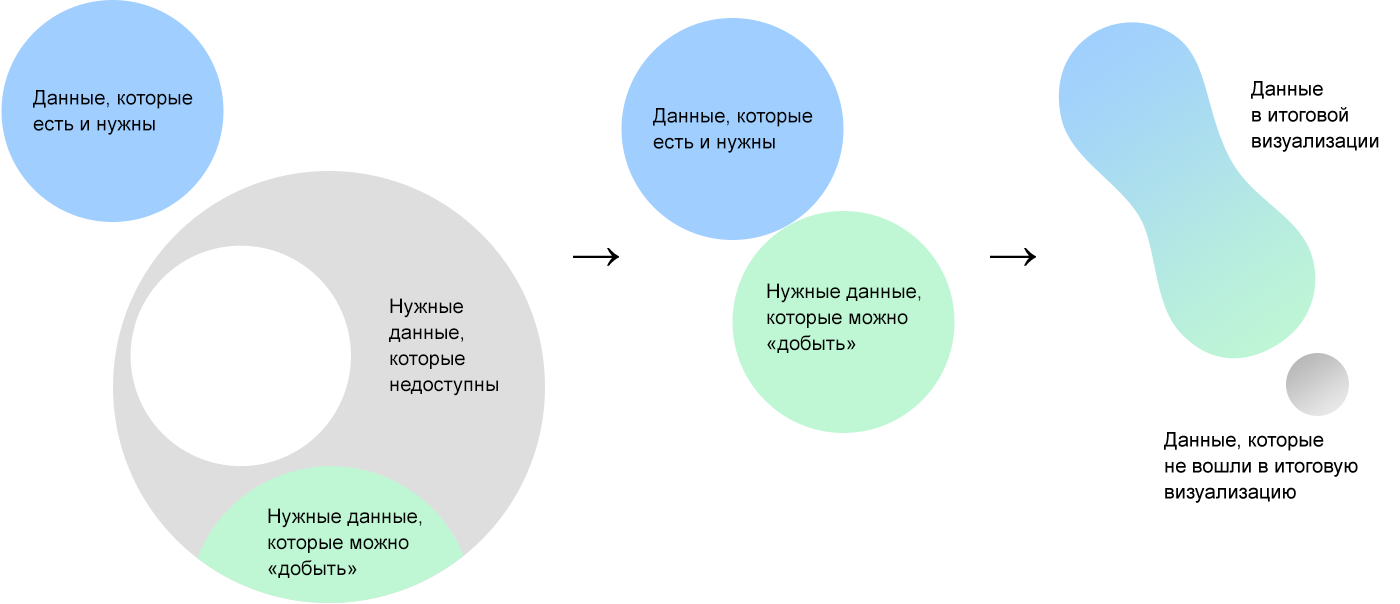
Эти данные мы и будем визуализировать. Таким образом на визуализации окажется максимально полезный из всех доступных слепок с реальности данных, а не разрозненный набор параметров.
Поясню на своём любимом примере — визуализации Московского марафона. На входе у нас финишные протоколы: имя, пол и возраст участника, номер, время финиша. В реальности данных толпа бегунов, каждый со своей скоростью преодолевает марафонскую дистанцию по улицам Москвы под палящим солнцем или в дождь. Мы хотим показать процесс, как бегут люди, идеальным будет набор данных с положением каждого бегуна, его скоростью, пульсом на всём протяжении забега, изменением высоты трассы и поминутно меняющейся погодой. Подробных данных о бегунах у нас нет и в ближайшее время не будет. Есть время финиша и прохождения 3-4 промежуточных точек на дистанции. По этим точкам можно аппроксимировать положение бегунов, пишем формулы, получаем координаты и скорость бегунов в каждый момент времени. Мы допускаем такую аппроксимацию, так как на больших отрезках марафонской дистанции движение плюс-минус равномерное, то есть порядок бегунов на трассе, за редким исключением, будет рассчитан правильно. Высоту подтягиваем с картографического сервиса, погоду и ветер берём из открытых источников. Собрав все эти данные воедино, начинаем колдовать над визуализацией.
Выходит, что ответ на большинство вопросов — здравый смысл. «Какие из этих грязных данных нас интересуют и могут помочь нам в ответе на вопросы задачи?» — те, что будут полезны для зрителя и помогут ему ответить на его вопросы. «Как их нужно преобразовать, чтобы нам было удобно с ними работать?» — так, чтобы было удобно работать. «Какие упрощения и допущения мы можем себе позволить в рамках этой конкретной задачи?» — те допущения, которые не нарушают общей картины и допустимы для решения этой задачи. «Как грязные данные сделать чистыми и связать с элементарными частицами и визуальными атомами?» — преобразовать, так чтобы было удобно работать, и визуализировать наиболее близкими по смыслу визуальными средствами. На последний вопрос как раз и отвечает алгоритм.

Как и обещала, три самых вдумчивых комментатора: Иван Печищев, Юлия Торгашова и Михаил Калыгин — получают скидку 5 тыс. руб. на осенний курс по визуализации данных. Огромное спасибо всем, кто отозвался!
Следующая теоретическая заметка выйдет 19 сентября.